GhostNet: More Features from Cheap Operations
본 글은 CVPR 2020에서 발표한 GhostNet에 대한 코드와 함께 보는 논문 리뷰입니다
간단 요약
- Ghostnet에서는 전통적인 CNN에서 나타나는 특징인 중복된 Feature(중요한 Feature)에 중점을 두고 이를 효율적으로 만들어 내는 방법에 대하여 작성된 논문입니다.
- 기존에 뽑아둔 Feature를 일반적인 Convolution 연산보다 적은 resource를 가지는 Linear Transfer연산을 통하여 조금씩 변형하여 중복된 Feature를 만드는 것에 초점이 잡혀있습니다
GhostNet : Idea
아래의 그림은 Resnet 50의 일부 Feature 맵을 시각화 한 사진인데, 여기서 보면 일부 비슷한 모습을 가지는 Feature Map을 볼 수 있습니다. 이를 본 논문에서는 이러한 겹치는 Feature를 Ghost Feature라고 서술하였습니다.
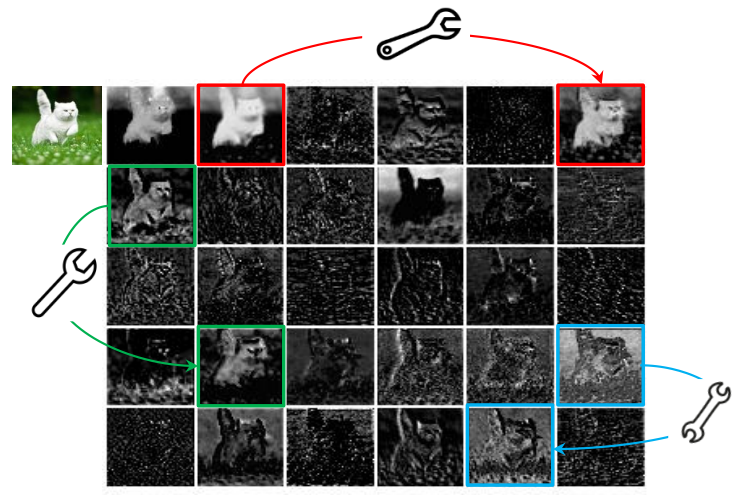
Ghostnet에서는 이러한 Ghost Feature map을 convolution 연산을 통해 자연스럽게 나오는게 아닌 Linear Transfer를 이용하여 기존의 뽑아낸 Feature를 조금씩 변형하여 만든 Feature맵으로 유도하여 적은 Parameter와 Flops를 가진 모델을 만드는 것을 목표로 합니다.
Ghost Module
기존의 CNN Block Module은 아래의 첫번째 그림과 같이 연산이 됩니다. 이 경우 필요한 Parameter의 수는 다음과 같습니다.
$c$ : channel수
$kernel$ : kernel size
$$
parameters = c_{in} \times c_{out} \times kernel
$$
두번째 그림에서 보여주는 Ghost Module은 다음과 같은 연산과정을 통하여 이루어집니다
- Input을 Convolution연산을 통하여 Feature를 추출
- 추출된 Feature에 Linear transformation을 통하여 기존의 Feature들과 유사한 Ghost Feature를 생성
- Feature와 Ghost Feature를 Concat을 통하여 하나로 합침
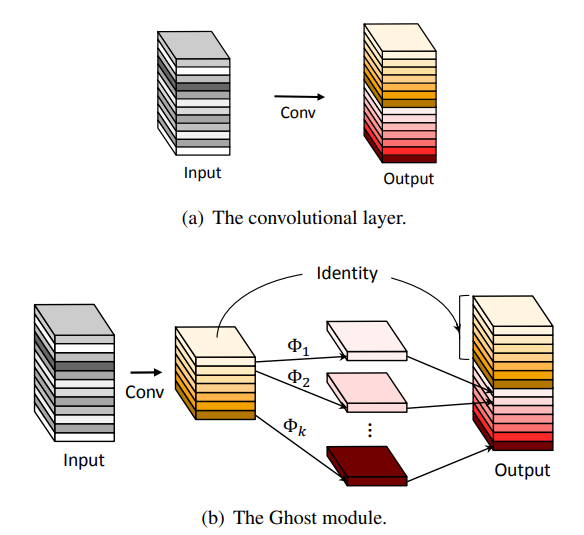
실제 구현에서는 Linear Transfer 연산으로 Mobilenet에서 사용되었던 Depthwise Convolution 연산을 사용하였습니다.
input이 80이고 output이 100인 연산을 convolution으로 만 진행할 경우 필요한 Parameters는 아래와 같지만
$$ 80 \times 100 \times kernel_{conv}$$
이를 Ghost Block으로 진행 할 경우 다음과 같이 Parameter가 줄게 됩니다.
- 기존 Feature와 Ghost Feature의 1:1 인 경우
$$
80 \times 50 \times kernel_{conv}+ 50 \times kernel_{dwconv}
$$
- torch의 Conv2d Layer는 group을 이용하여 depthwise Convolution 연산을 진행 할 수 있습니다.
- group이 output사이즈와 같을경우 depthwise 연산을 진행
1 | class GhostModule(nn.Module): |
코드 출처 : huawei-noah/Efficient-AI-Backbones
Ghostnet은 CNN 중복된 Feature 특징 통하여 딥러닝 모델에서의 Feature가 서로 상관관계가 있고, 이를 기존 Feature를 통해 생성하면서 좋은 결과를 보여주었습니다.
데모
GhostNet은 pytorch hub를 통하여 손쉽게 Classification 모델로 사용할 수 있습니다.
- 모델 Load
1 | import torch |
- Classification
1 | from PIL import Image |