부스트 캠프 ai tech 1주 4일차 Ai Math (8)
8. RNN
- 연속적인 데이터(Sequence Data)를 주로 다루는 Nerual Network
- 소리, 문자열, 주가등의 데이터를 분석하는데 사용된다
8.1 시계열 데이터
독립동등분포 가정을 잘 위배하기 때문에 순서를 바꾸거나 과거에 정보에 손실이 발생하면 데이터의 확률분포 자체가 변해버린다
베이즈 법칙을 이용하여 다음과 같이 표현이 가능하다
$$
\begin{aligned}
P(X_1, … ,X_{t}) & = P(X_t|X_1, …, X{t-1})P(X_1,…,X_{t-1})\\
& = \prod_{s=1}^{t}P(X_s|X_{s-1},…,X_1)
\end{aligned}
$$시퀸스 데이터를 다루기 위해서는 길이가 가변적인 데이터를 다룰수 있는 모델이 필요하다
- 조건부에 들어가는 데이터의 길이는 시퀸스마다 가변적이다
$$
\begin{aligned}
X_t &\sim P(X_t|X_{t-1}, … X_{1})\\
X_{t+1} &\sim P(X_t|X_{t}, X_{t-1}, … X_{1})
\end{aligned}
$$
- 조건부에 들어가는 데이터의 길이는 시퀸스마다 가변적이다
고정된길이 $\tau$ 만큼의 시퀸스만 사용하는 모델의 경우 자기회귀모델(Autoregressive Model)이라고 한다
- 매우 오래된 과거의 데이터는 실제 데이터에 큰 영향을 주기 힘들다는 가정하에 세워진 모델이다
$$
\begin{aligned}
X_t &\sim P(X_t|X_{t-1}, … X_{t-\tau})\\
X_{t+1} &\sim P(X_t|X_{t}, … X_{t-\tau+1})
\end{aligned}
$$
- 매우 오래된 과거의 데이터는 실제 데이터에 큰 영향을 주기 힘들다는 가정하에 세워진 모델이다
이전정보를 제외한 나머지 정보들을 잠재변수로 활용하는 모델을 잠재자기회귀모델 이라고 한다
- 앞으로 다룰 RNN도 이 모델에 해당한다
$$
\begin{aligned}
X_t &\sim P(X_t|X_{t-1}, H_t)\\
X_{t+1}&\sim P(X_t|X_{t}, H_{t+1})\\
H_t&=\operatorname{Net}(H_{t-1}, X_{t-1})
\end{aligned}
$$
- 앞으로 다룰 RNN도 이 모델에 해당한다
8.2 RNN
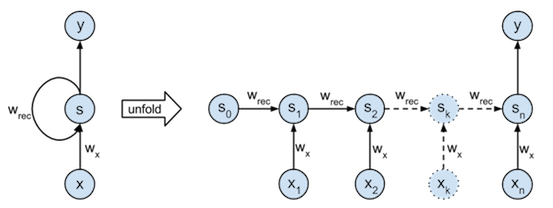
- 기본적인 RNN 모델은 아래와 같이 MLP와 유사한 형태를 가지고 있다
- RNN은 이전순서의 잠재변수와 현재의 입렬을 활용하여 계산을 이어나간다
- RNN의 역전파는 BPTT(Backpropagation Through Time)라고 불리며 연결그래프에 따라 순차적으로 계산한다
- $S$ : 잠재변수
- $X$ : input Data
- $W_x$ : $X$의 가중치행렬
- $W_{rec}$ : $S$의 가중치 행렬
- $\sigma$ : Activate Function
- $X$ : 시퀸스 데이터
- RNN의 Network 연산
$$
\mathbf{S_{t}} = \sigma (\mathbf{O}_{t-1} + \mathbf{X}_{t}\mathbf{W}_{x})
$$
$$
\mathbf{O_{t}} = \mathbf{S}_{t}\mathbf{W}_{rec}
$$
- BPTT
- RNN의 Backpropagation 을 계산해보면 미분의 곱으로 이루어진 항이 계산된다
- 시퀸스의 길이만큼의 $W_{rec}$의 역전파가 이루어 질 때 마다 계속해서 미분을 하기 때문에 시퀸스의 길이가 길어질수록 gradient vanishing(기울기 소실)이 발생하여 계산이 불안정해 진다
- $L$ : loss 함수
- $y$ : target
$$
\frac{\partial S_{t}}{\partial W_{rec}} = \sum_{i=1}^{t-1} \left( \prod_{j=i+1}^{t} \frac{\partial S_{j}}{\partial S_{j-1}} \right)\frac{\partial S_{i}}{\partial W_{rec}} + \frac{\partial S_{t-1}}{\partial W_{rec}}
$$
- truncated BPTT
- RNN은 시퀸스의 길이가 길어지면 기울기 소실이 발생하여 계산이 불안정해지기 때문에 중간에 연산을 끊어주는 테크닉.
- 이러한 기울기 소실을 해결하기 위해 등장한 네트워크
- LSTM, GRU
부스트 캠프 ai tech 1주 4일차 Ai Math (8)
https://kyubumshin.github.io/2022/01/20/boostcamp/week/week1/AIMath-8/