부스트 캠프 ai tech 2주 4일차 Pytorch (6)
7. Multi GPU 학습
- 데이터의 양이 방대해짐에 따라서 모든 데이터들을 전부 메모리에 올리는것이 물리적으로 힘들고, 시간적으로도 소요가 많이 되어서 이를 해결하기 위해 여러대의 GPU를 병렬적으로 사용하는 방법이다
- 크게 2가지의 방법으로 나뉜다
- Model 병렬화 : 모델을 나눠서 학습한다
- Data 병렬화 : 데이터를 나눠서 학습한다
7.1 Model 병렬화
모델을 나눠서 여러대의 GPU에 올려서 연산하는 방법
모델의 크기가 너무 커서 GPU에 올라가지 않는 상황에서 사용한다
모델의 병목화, 파이프라인 구축 등의 문제로 인해 구현 난이도가 높다
- pipeline을 제대로 구축하지 않으면 한 GPU가 연산하는동안 다른 GPU가 놀고있는 상황이 발생해 오히려 Single GPU보다 못한 상황이 발생 할 수 있다
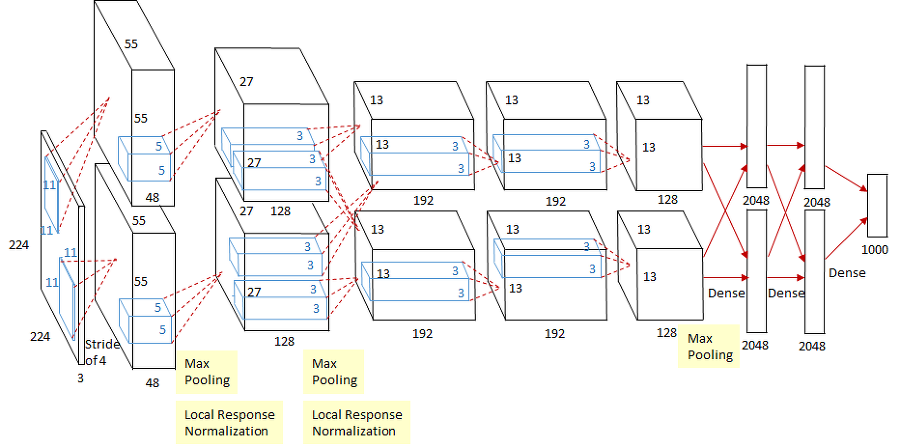
Model Pipeline Paralle 예시 - Pytorch 공식 모델 병렬화 Tutorial
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. s_prev는 두 번째 GPU에서 실행됩니다.
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. s_next는 A.와 동시에 진행되면서 첫 번째 GPU에서 실행됩니다.
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)아래의 그림에서 2장의 레이어 사이에 교차하는 부분이 병렬 GPU간의 교차 통신이다
- Model 병렬화는 꽤 예전 논문인 AlexNet에서도 사용되고 있었다
7.2 Data 병렬화
- 데이터를 나눠서 GPU에 할당한 후 결과의 평균을 취하는 방법
- 각 데이터에 대한 연산을 여러 GPU에서 동시에 수행해서 학습의 효율을 높인다
- 합칠때
- pytorch에서는 두 가지 방식을 제공한다
- DataParallel : 단순하게 데이터를 분배한 뒤 평균을 취하는 방식
- Distributed DataParallel : GPU에서 모든 연산이 끝난뒤에 결과만을 공유하는 방식
- DataParallel:
- 단순하게 GPU에 데이터를 분배한 뒤 평균을 취하는 방식
- 연산이 끝난뒤에 하나의 GPU에 loss값을 모아서 gradient를 만들고 이것들 다시 다른 GPU에 전달을 해준다
- 하나의 GPU가 특별하게 자원을 많이 사용하는 문제가 발생할 수 있다
- 합쳐진 loss연산을 GPU는 더 많은 메모리를 사용하기 때문에 Batch사이즈의 감소등의 방법으로 메모리 부하를 줄여야 할 수도 있다
- 매우 간단하게 pytorch에서 구현 할 수 있다
1
parallel_model = torch.nn.DataParallel(model) # 나머지는 일반 모델과 동일
- Distributed DataParallel:
- GPU에서 모든 연산이 끝난뒤에 결과만을 공유하는 방식
- Loss, Backward 계산 모두 각각의 GPU에서 이루어지며 연산이 완전히 끝나고 평균값이 결과로 출력된다
- 개별 GPU마다 CPU에서 프로세스를 생성해서 할당한다 (Multiprocessing)
- DataParallel과는 다르게
DataLoader에서 Shuffle 대신에 DistributeSampler를 사용하고, pin_memory를 활성화 시킨다
reference
부스트 캠프 ai tech 2주 4일차 Pytorch (6)
https://kyubumshin.github.io/2022/01/27/boostcamp/week/week2/pytorch-8/