부스트 캠프 ai tech 9주 2일차 Conditional Generative Model
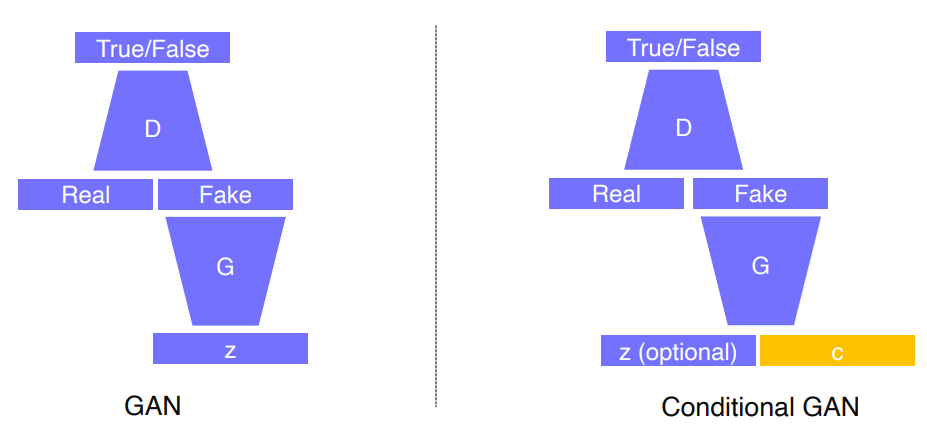
Conditional Generative Model
사용자가 컨트롤이 가능한Generative Model- 서로 다른 두 도메인을 변화시켜주는 Task
- 통역모델, 음성의 고품질 전환, 요약모델 등 다양한 분야에서 응용가능하다
Conditional GAN
랜덤으로 생성되는 Latent Noise z 만 받는 GAN과는 다르게 latent Noise z + Conditional Input이나, domain Data의 형식으로 받는다
- CV 응용분야
- Style Transfer
- Super resolution
- Colorization
Super Resolution
- 해상도가 낮은 이미지를 높은 이미지로 변환시키는 Task
- Super Resolution을 위한 기존의 Naive Regression model에서는 MAELoss나 MSELoss를 사용
- MAE와 MSELoss는 이미지를 전체 이미지의 평균값으로 생성하는 경향이 존재해서 이미지가 뿌옇게 생성됨
- Super Resolution GANLoss를 이용하여 좀더 선명한 품실의 image를 얻어냈다
- GAN Loss는 전체 이미지의 분포로 접근해서 생성하는 경향이 있었기에 MAE, MSE에 비해서 덜 뿌연 이미지를 생성
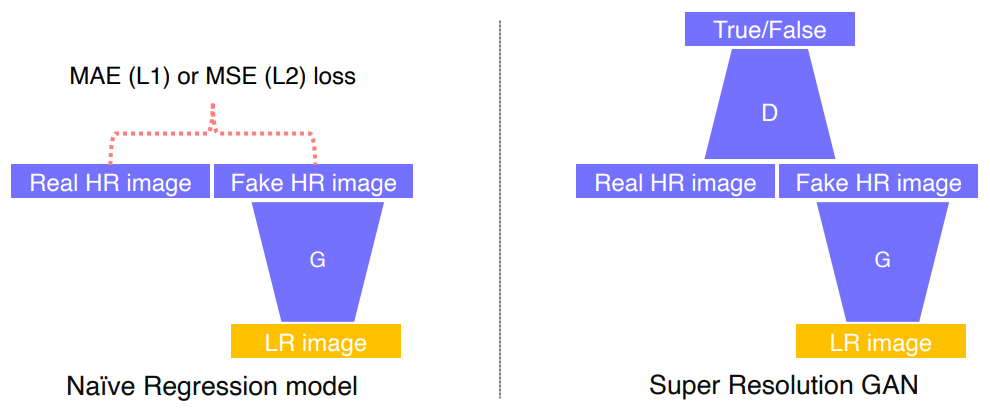
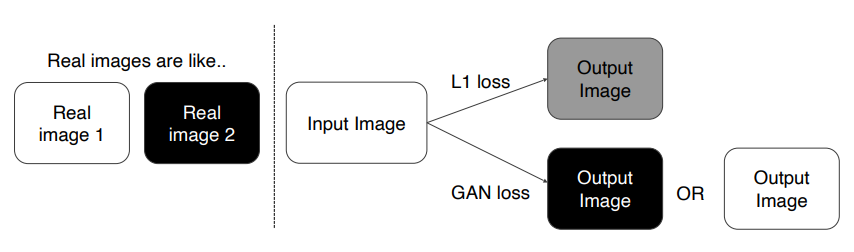
Image Translation Model
Pix2Pix
Image Translations Task를 위한 GAN model
Generator는 Segmentation Masking Data를 사용하여 이미지를 생성한다
Discriminator는 Segmentation Masking Data + image를 가지고 진짜인지 가짜인지 판별한다
Total Loss
- GAN Loss + L1 Loss
- 논문에서는 GAN Loss로 Cross Entropy를 사용
- L1 Loss : 형태는 Ground Truth와 비슷하지만 Blurry한 이미지가 생성
- GAN Loss : Sharp한 이미지가 형성되지만 형태가 불안전한 이미지가 생성
- GAN Loss + L1 Loss
$$
G^{*} = arg, \underset{G}{min}, \underset{D}{max}, \mathcal{L}_{cGAN}(G,D) + \lambda \mathcal{L}_{L1}(G)
$$

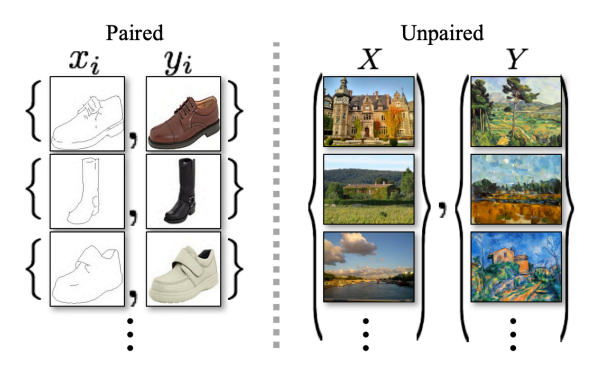
CycleGAN
- Pix2Pix와 같은 Image Translation Model 이지만 Unpair Data를 변환시켜줄 수 있다
- Pix2Pix의 Pair Image라는 제약상황에서 벗어날 수 있다
- Generator
- Input으로 변환시킬 Image를 받는다
- Unet의 Decoder처럼 단계적으로 Size를 확장시키면서 생성하는구조의 Generator를 가진다
- Discriminator
- Input으로 Image를 받고 Real, Fake를 판단
- PatchGAN의 형태를 가짐
- CycleGAN에서는 2개의 Discriminator와 2개의 Generator가 존재해서 서로 Cycle을 이룬다
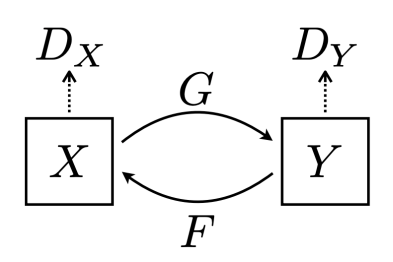
- Total Loss
- GAN Loss + Cycle Consistency Loss
- GAN Loss : adversarial losses를 적용
- Cycle Consistency Loss : mode collapse 문제를 막기위해 도입한 함수
- 변환된 이미지를 재변환(reconstruct)시켰을 때 Real Image사이의 L1 Distance Loss
$$
\mathcal{L} = \mathcal{L}_{GAN}(X \rightarrow Y) + \mathcal{L}_{GAN}(Y \rightarrow X) + \mathcal{L}_{cycle}(G, F)
$$
Perceptiaul Loss
GAN은 학습시키기 힘들다
High quality output을 위한 Loss
Adversarial Loss
- 학습과 구현의 난이도가 높다
- Data 만 존재하면 Pretrained 모델이 없어도 좋은 성능을 낼 수 있다
Perceptiaul Loss
- 학습 및 구현의 용이성
- Pretrained 모델을 통해서 만 구현이 가능
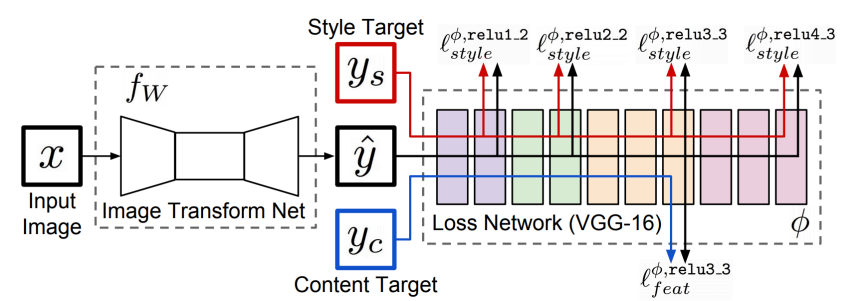
Perceptiaul Loss 구조
Perceptiaul Loss는 다음과 같이 이미지를 변환시켜주는 Image Transform Network과 pretrained Model로 이루어진 Loss Network 2개로 구현 할 수 있다.
우선 Image Transform Network는 바꿀 이미지를 넣어서 새로운 이미지로 생성하는 역할을 한다. Loss Network는 생성된 이미지 $\hat{y}$, 이미지를 바꾸고싶은 Style Target $y_{s}$와
reference
부스트 캠프 ai tech 9주 2일차 Conditional Generative Model
https://kyubumshin.github.io/2022/03/14/boostcamp/week/week9/CNN-6/