부스트 캠프 ai tech 9주 3일차 Multi-modal Learning
Multi-modal Overview
- Unimodal : 하나의 특징 Data로 학습시키는 기법
- Multi-modal : 여러가지의 Data로 학습시키는 기법
Difficultiy of Multi-modal
- 데이터마다 표현방법이 모두 다르다
- Audio : wave
- Image : pixel
- text : sequence? query?
- 데이터간의 Unbalance한 Feature map
- 데이터 자체의 종류가 다르기 때문에 생성하는 분포의 차이가 클 가능성이 높다
- 학습시키기 용이하지 않음
- 항상 Multi-modal이 좋은방법은 아니다
- 전체 모델에서 한 데이터에 집중하여 학습하면서 다른 데이터를 소홀히 하는 편향적인 학습이 이루어 질 가능성이 존재한다
Multimodal Learning
- Matching : 두 데이터에 대해서 같은 공간으로 매칭시키도록 학습
- Translating : 한 데이터를 다른 데이터로 변형 시키도록 학습
- Referencing : 참조를 통한 상호보안적으로 더 좋은 결과를 내게 학습

Image & Text
NLP Preview
Text Embedding
- Text Map to vector
- Text를 1차원 Vector로 변환해서 공간상에 표현하는 방법
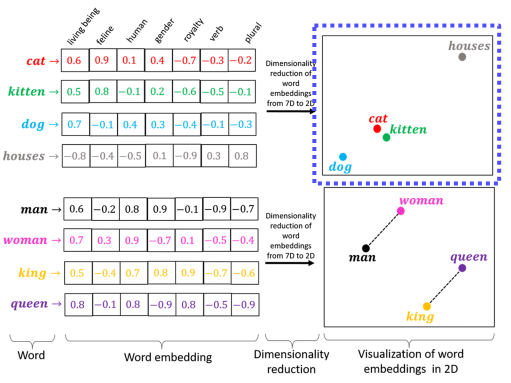
Word2vec
*
Joint embedding
- Matching 기법을 사용해서 만들어진 Multi-modal
- Pretrained unimodal Model을 합쳐서 사용하는 기법
두 가지의 Data로 부터 같은 차원의 Feature를 추출하고, 이것을 Joint Embedding 시켜서 Matching 이 이루어지는 같은 데이터는 높은 Metric, Matching 되지않는 데이터는 낮은 Metric을 부여하도록 학습시키는 방법이다.
- 같은 차원의 Feature로 추출하는 이유
- 하나의 Feature Dimension상에서 Metric을 계산해야한다
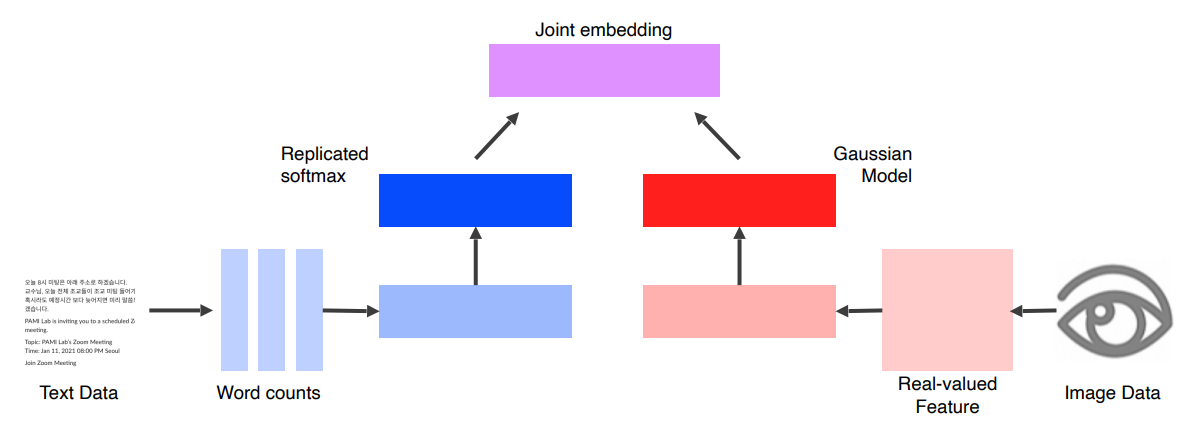
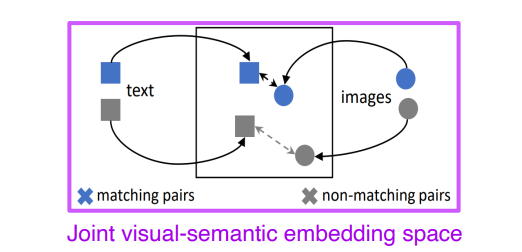
Image Tagging
- 주어진 이미지에 대해서 Tag를 붙여주거나, 여러가지 Tag에 맞는 이미지를 검색해 주는 모델
- Distance를 Metric으로 사용한 모델
- Tag를 추가하거나 빼면 기존의 이미지와 유사하면서 바뀐 Tag만 적용될만한 이미지를 우선적으로 뽑아주는 결과를 얻었다

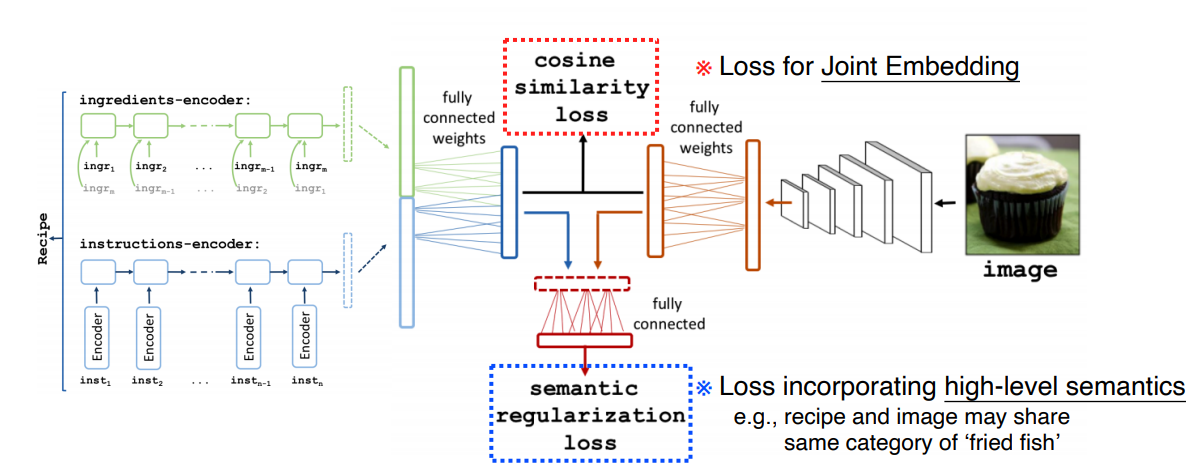
Recipe text vs food image
- 주어진 요리 사진에 레시피를 출력해주거나 레시피를 입력했을때 매칭된 이미지를 뽑아주는 모델
- cosine similarity와 semantic regularization loss를 이용하였다
- cosine similarity : text data와 image로 뽑은 Feature가 얼마나 유사한지를 계산
- semantic regularization loss : 공통된 요리 카테고리에 속해있는지를 계산해서 반영한다 (성능을 높이기 위해 보정)
Cross modal translation
- Translating 기법을 사용한 모델
- 모델에서 뽑은 Feature를 input으로 다른 모델에 넣고 변환시킨다.
- Data를 Feature로 바꿔주는 첫 모델을 Encoder, Feature로 Output를 뽑아내는 모델을 Decoder라고 지칭한다
Show attend and tell
- CNN을 통해서 Feature를 추출
- 추출한 Feature를 바탕으로 RNN에 입력
- RNN 에서는 단어를 예측하면서 다음에 참조할 Feature map을 선택한다
- 위의 과정이 반복되면서 문장을 생성한다
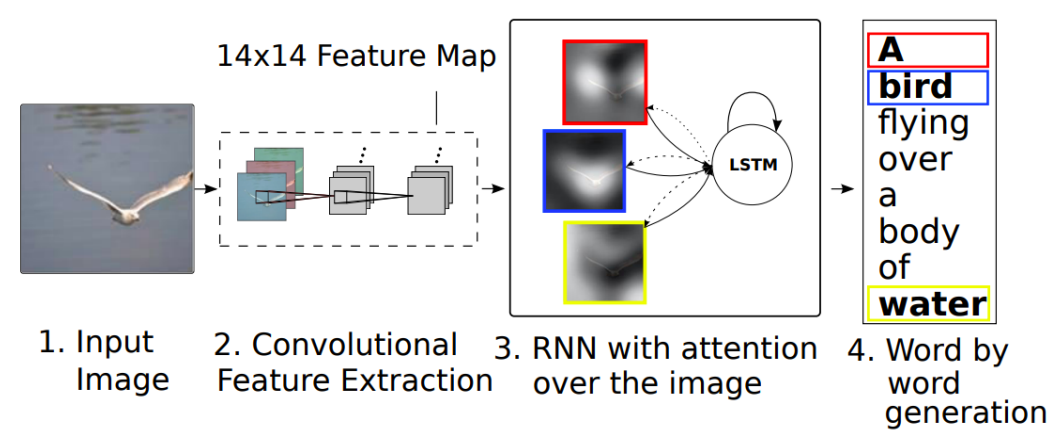
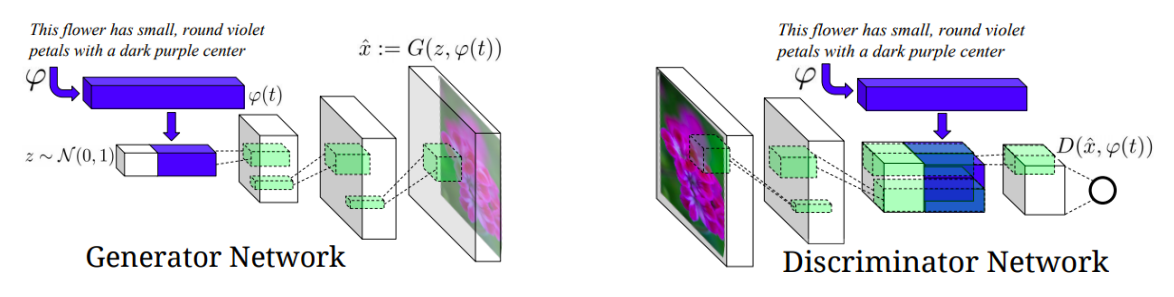
Text2Image
- Text에서 image를 생성하는 모델
- Conditional GAN을 통해서 구현 하였다
- Encoder를 통해서 Text로 부터 Feature를 얻는다
- Feature를 Conditional Input으로 Conditional GAN을 학습시킨다
Cross modal reasoning
- Referencing 기법을 통해 학습시킨 모델
- 두 모델에서 나온 Feature로 Joint embedding을 진행하고 추가적으로 Layer를 배치하여 하나의 Task를 푸는 형태로 디자인 되어있다
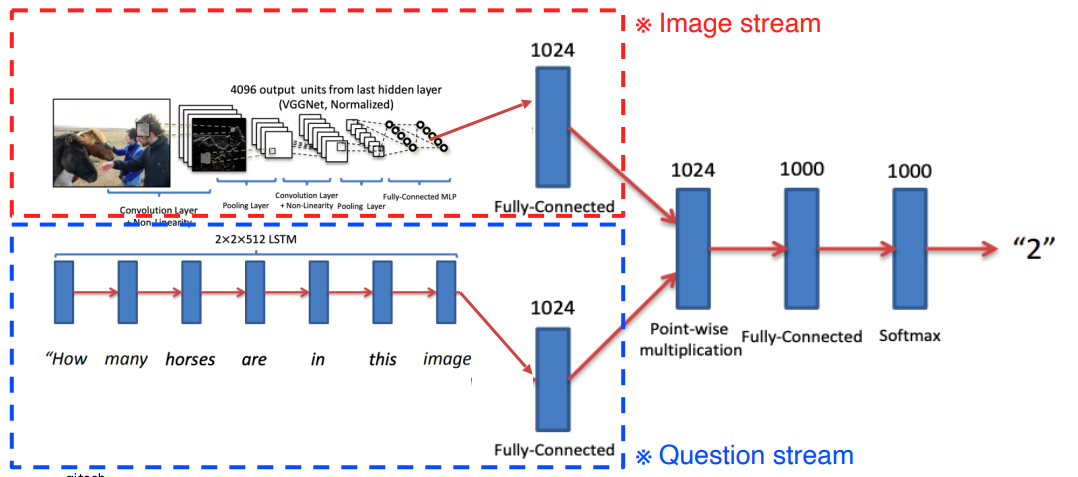
- 위의 Show attend and tell은 Translating와 Referencing이 둘다 사용된 모델이다
- 실제로 학습할 때는 word token을 같이 받음
reference
부스트 캠프 ai tech 9주 3일차 Multi-modal Learning
https://kyubumshin.github.io/2022/03/16/boostcamp/week/week9/CNN-7/