부스트 캠프 ai tech 9주 4일차 3D perspective
3D
- 사람은 Projection된 2D 이미지로 부터 3D를 인식한다
3D의 표현방법
- Multiview images
- 여러 방향에서 찍은 사진데이터로 표현
- Volumetric (voxel)
- x, y, z의 3차원 pixel로 3D를 표현
- Part assembly
- 단순한 여러개의 Polygon 덩어리로 3D를 표현
- Point cloud
- 물체의 surface을 dot의 좌표로 표현
- Mesh
- point와 edge로 이루어진 map
- 3각형으로 이루어진 Polygon Data
- implicit shape
- 고차원의 함수형태로 surface를 표현

3D Dataset
ShapeNet
- 51300개, 55개의 Category를 가진 3D Dataset
- 전부 디자이너들이 제작함
PartNet
- 26671개의 3D 데이터가 573585개의 Part로 분리되어있는 3D Dataset
SceneNet
- 5 Million개의 RGB-Depth Pair Dataset
- Simulationed indoor image(생성 이미지)
ScanNet
- 2.5 Million
- 실제 Indoor Scan Image
Outdoor 3D Scene Dataset
- KITTI
- LiDAR Data, 3D Bboxes
- Semantic KITTI
- LiDAR Data, point
- Waymo open Dataset
- LiDAR Data, 3D Bboxes
3D Task
- 3D object recognition
- 3D object detection
- 3D semantic segmentation
Conditional 3D generation
- 2D Image에서 3D Mesh를 구하는 Task
- Mesh RCNN
- 기존 Mask RCNN 에서 Mesh Branch를 추가한 형태

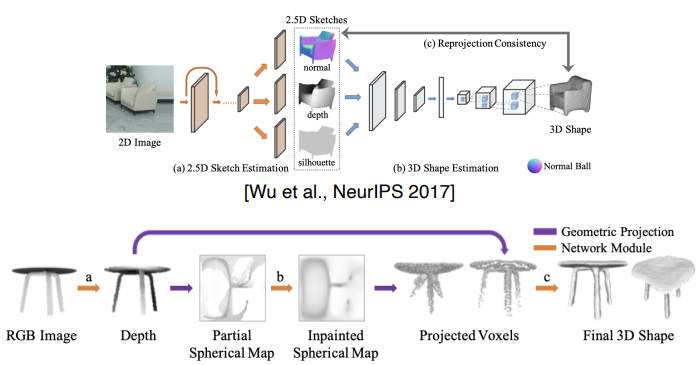
- Learning to Reconstruct Shapes from Unseen Classes
- CNN구조로 부터 Feature 추출
- 3개의 Branch로 Feature 재생성
- normal map
- depth
- silhuette
- 재구성을 통한 3D shape 출력
reference
부스트 캠프 ai tech 9주 4일차 3D perspective
https://kyubumshin.github.io/2022/03/18/boostcamp/week/week9/CNN-8/