Activation Function
활성화 함수 Activation Function
- 실수범위에서 정의된 비선형 함수
- 딥러닝을 비선형 모델로 만들어주는 결정적인 함수이다
1. softmax
- 분류 모델에서 많이 사용하는 함수
- 출력값은 항상 0~1사이로 정규화된다
- 보통 활성화 함수로는 사용되지 않고 마지막 단계에서 출력을 정규화할때 사용한다.
$$
f(x)_{k} = \frac{e^{x_i}}{\sum_{k=1}^{n}e^{x_{k}}}
$$
- 보통 활성화 함수로는 사용되지 않고 마지막 단계에서 출력을 정규화할때 사용한다.
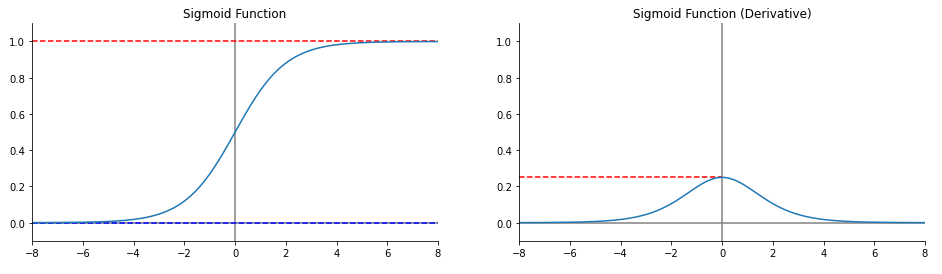
2. sigmoid
- 출력값을 0~1 사이로 변경한다
- 위의 softmax 함수의 원형
- 함수의 단점
- 중심이 0이 아니기 때문에 모든차원이 같은방향으로 이동한다
- 값이 커질수록 기울기 값이 감소한다
$$
\sigma(x) = \frac{1}{1+e^{-x}}
$$
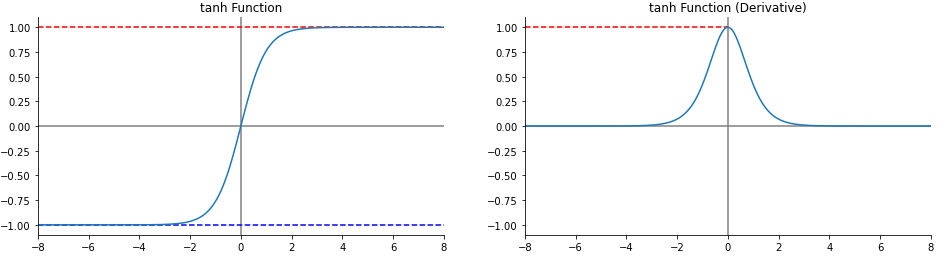
3. Tanh
- sigmoid함수의 개량형
- 중심을 0으로 맞춰서 sigmoid 함수의 단점을 줄였다.
- 하지만 여전히 기울기 값의 감소에 따른 Gradient vanishing 문제가 존재한다
$$
tanh = 2\times \sigma(2x) -1
$$
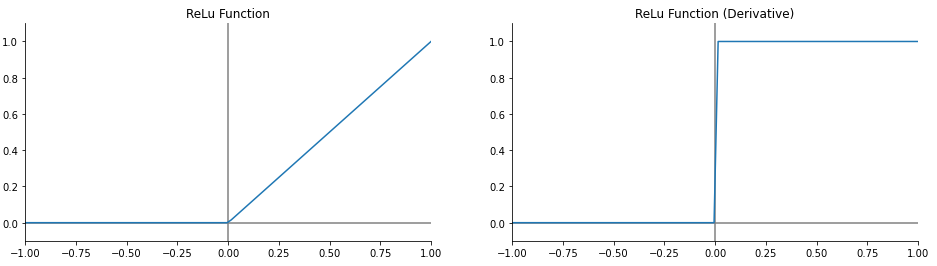
4. ReLU
- 0보다 크면 그대로 넘기고 작으면 0으로 만드는 매우 간단한 함수
- sigmoid 계열에 비해 연산속도가 매우 빠르다
- 큰값이 와도 기울기 값이 유지되기 때문에 gradient vanishing이 해소되었다.
- 단점
- 큰 값이 연속될 수 있는RNN 계열에서는 Gradient exploring이 발생한다.
- 0 이하의 값이 무시되기 때문에 음수값만 존재하면 weight가 죽어버리는 Dying ReLU현상이 일어난다
$$
\operatorname{ReLU} = max(0, x)
$$
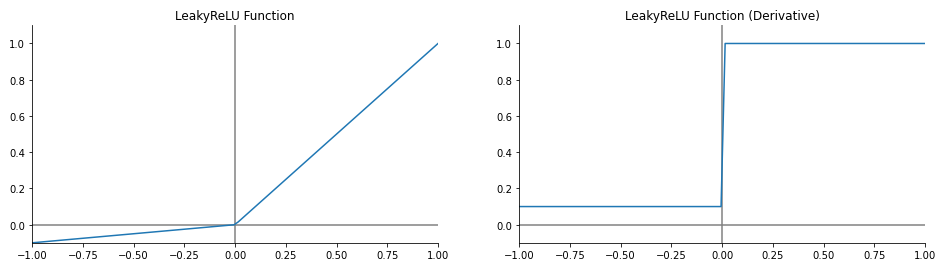
5. Leaky ReLU
- Dying ReLU 현상을 해결하기위해 고안된 활성화 함수
- 0보다 작은값에는 $\alpha$값을 곱한다
- GAN 계열의 Generator에서 많이 사용된다
- 단점
- 여전한 Gradient exploring
$$
\operatorname{Leaky ReLU} = max(\alpha x, x)
$$