Garbage Collector(이하 GC)는 메모리 관리 기법중 하나로 동적으로 할당했던 메모리 영역 중에 필요없게 된 부분을 해제하는 기능이다. C, C++등의 언어들은 수동메모리 관리를 전재로 설계되어 malloc, free등의 함수로 직접 메모리를 관리 해주어야 하지만, Python, Java, C# 같은 고급 언어들은 GC가 내장되어 있어 자동으로 메모리 관리를 해준다.
Python GC의 작동방식
Python의 GC는 reference count + Generational GC 방식으로 메모리를 관리한다.
python의 객체들은 모두 reference count를 가지고 있으며 이것을 통해서 GC가 언제 메모리에서 제거할지를 판단한다. 참조가 이루어지면 reference count가 1증가하고, 참조가 끝나면 1감소한다. 최종적으로 0이 되면 GC에서 더이상 필요없는 오브젝트로 판단하고 메모리에서 삭제한다.
이러한 방식은 프로그래머가 어느정도 오브젝트의 메모리 할당 해제 시점을 유추 할 수 있고, 대부분 사용된 직후 해제되기 때문에 캐시에 저장되어 있을 확률이 높아 빠르게 할당 해제가 이루어지는 장점이 존재한다.
하지만 아래와 같은 단점 또한 존재한다. 두개 이상의 객체가 서로 가리키고 있을 경우(순환 참조) reference count가 0까지 내려가지 않는 상황이 발생 할 수 있다. 또한 Multi Thread 환경에서는 공유자원에 대한 참조가 되기 때문에 추가적인 Lock 등이 필요하거나, 지속해서 GC에서 판단하는 프로세스를 거쳐야 하기 때문에 수행 성능의 저하 등의 문제가 발생 할 수 있다.
이러한 단점들을 해결하기 위해 Python에서는 순환 참조를 탐지하는 알고리즘과, 보조적인 Generational GC를 두었고, GIL로 Multi Threading에 제한을 걸어 버렸다.
Generational GC
새롭게 할당된 오브젝트일수록 금방 메모리에서 해제될 확률이 높다는 통계에서 기반한 메모리 관리방법이다. 각각의 오브젝트가 GC가 실행하고나서 메모리에서 해제되지 않으면 다음 세대로 넘어가게 되는 방식인데 더 젊은 세대(금방 생성)일수록 자주 GC의 프로세스에서 할당 해제할 오브젝트인지 판단이 내려지게 된다.
이 과정을 보조적으로 추가하면서 python에서는 조금더 효율적으로 메모리를 관리 하고 있다.
Global Interpritor Lock(GIL)이란 Python에서 오직 하나의 Thread만 동작하도록 컨트롤하는 Lock(또는 Mutex)이다. 이 말은 타임라인상에 오직 하나의 Thread만 실행될 수 있다는 것을 말한다. Single Thread를 사용하는 코드에서는 그렇게 큰 영향을 주지 않지만, Multi-Thread를 사용하는 코드에서는 병목현상을 일으킬 수 있다.
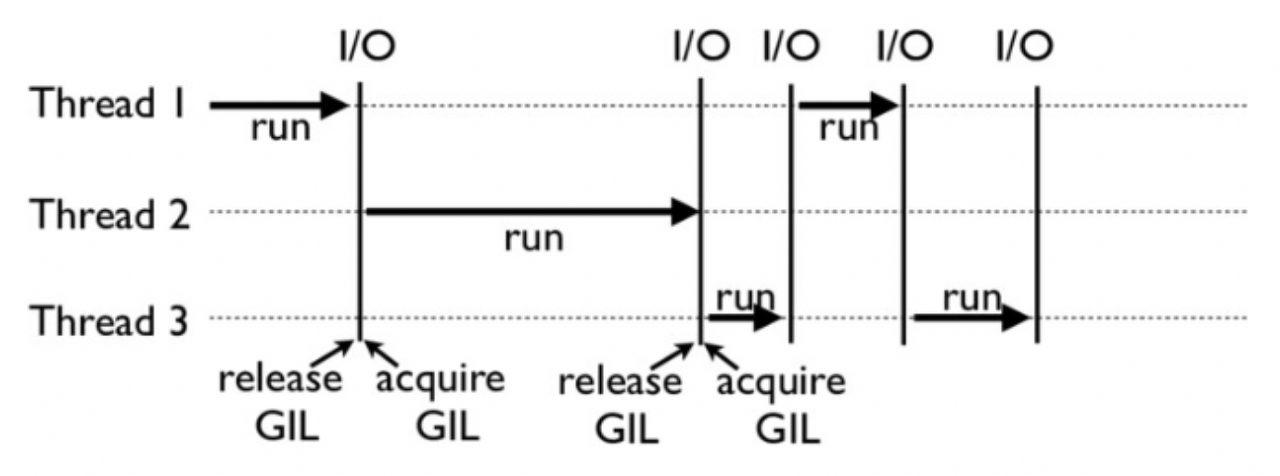
GIL이 어떻게 동작하는지 한번 살펴보자
위에서 이야기 한 것처럼, GIL에서는 오직 하나의 Thread만 활성화되어서 코드를 실행하는데 이는 아래의 그림처럼 그려낼 수 있다.
Thread가 전환 될 경우에는 기존의 Thread의 작동이 멈추고 동작을 시작하게 된다. 기존의 하던 작업들을 멈추고 다른 Thread로 넘겨야 하기 때문에 context switch가 일어나게 된다.
그러면 왜 GIL을 사용할까?
먼저 왜 GIL을 사용하는지 알기 위해서는 Python의 Garbege Collector(GC)에 대해 알고 있어야 한다. (GC에 대한 자세한 내용은 추후에 다룰 예정이다) 고급언어인 python에서는 C언어와 다르게 자동으로 메모리 관리를 해주는 GC라는 것을 사용한다.
이 GC는 오브젝트가 얼마나 많이 참조(실행)가 되었는지를 카운팅하는 reference count 라는 것으로 메모리에서 삭제할지 유지할지를 결정한다. 하지만 동시에 여러군데에서 참조가 이루어 질 경우 Race Condition 등의 문제들이 발생 할 수 있기 때문에 이를 방지하기위해 Mutex나 Semaphore등의 Lock이 필요했는데 이것을 Python에 존재하는 수많은 Object에 전부 적용하는것은 성능상으로도 좋지 않을 뿐만 아니라, Deadlock 같은 매우 치명적인 위험상황이 발생 할 수 있었다
그래서 선택한것이 따로 Object에 Lock을 두지 않고, 타임라인에서 실행되는 Thread를 딱 하나만 두도록 Interpritor를 Mutex로 잠궈버렸다. 이렇게 되면 여러곳에서 동시 참조가 되지않으니 성능의 하락 없이 위의 동시참조의 문제를 해결하게 된것이다
그러면 python에서는 병렬화된 코드는 어떻게 써야하나
Multi Process를 사용한다 Thread를 막아버린것 이기 때문에 Multi Processing을 사용하면 잘 돌아간다. 물론 Process간에 공유자원을 가지기 위해서는 많은 작업들이 필요로 하기 때문에 context switching이 발생하여 Thread에 비해 속도가 늦을 것이다. 하지만 Windows는 OS 보안상 이유로 이걸 막아버렸다.
Multi Threading을 사용한다 아까 Multi Threading을 막아놨다고 했는데 뭔 소리냐 할 수 있지만, CPU에서 대부분의 연산이 돌아가는 코드를 제외한 I/O Bound 계열의 문제들은 file system과 Network의 하위 컴포넌트에서 돌아가기 때문에 Single보다 더 빠르게 진행 할 수 있다.
굳이 사용하고 싶다면 PyPi나 Jython 같은 다른 Python implementation으로 사용하는 방법도 존재하지만, 그 코드가 python에서와 똑같이 동작할 보장은 없다
그리고 numpy나 Scipy등의 ML에서 많이 사용하는 Module들은 C기반으로 만들어져서 GIL의 굴레에서 자유롭게 연산이 된다고 한다.