Instance Segmantation
- Pixel 단위의 Classification 뿐만 아니라 객체간의 구분도 판단하는 Task
Mask R-CNN
- Faster R-CNN를 기반으로 Instance Segmentation Task를 해결하기 위해 디자인된 모델
- Keyword
- RoI-Align
- Mask Branch(head)
RoI Align
기존 RoI Pooling은 반올림을 해서 Pooling을 연산해서 조금 부정확 하더라도 BBox를 찾는것이기 때문에 괜찮았지만, Segmentation Task에서는 Mask가 이질적으로 변할 가능성이 있기 때문에 소수점 자리까지 연산이 가능하도록 한 RoI 기법
Mask Branch
Faster RCNN의 Neck에서 BBox 별로 추출한 Feature에 따로 Mask Branch를 두어 Binary Classfication을 수행한다
YOLOACT
YoloActEDGE
Panoptic Segmentation
Instance + Semantic Segmentation Task
UPSNet
Backbone Network를 통해서 뽑은 Feature를 이용하여 Semantic, Instance Feature로 가공한 뒤 Panoptic head로 합치는 과정을 거치는 모델
- Keypoint
- 3개의 head
- Semantic head
- Instance head
- Panoptic head
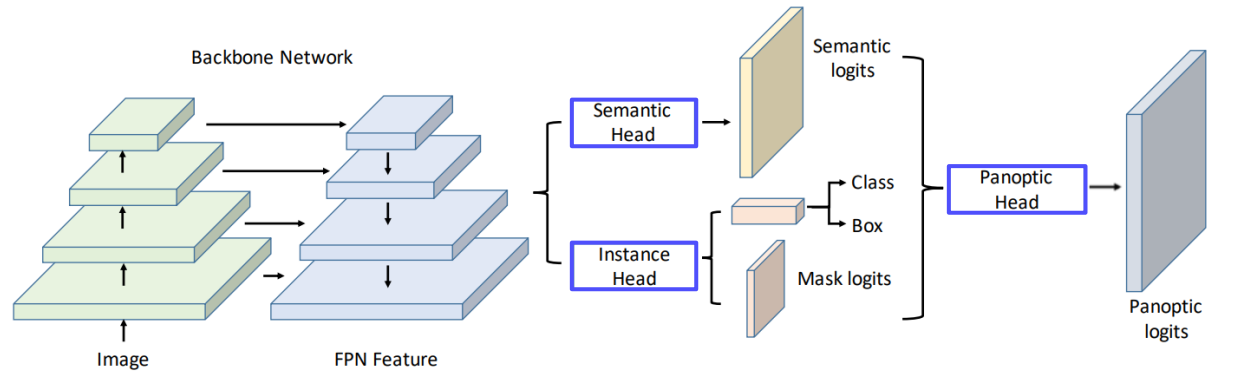
Heads Design
- Instance Head
- Semantic Head
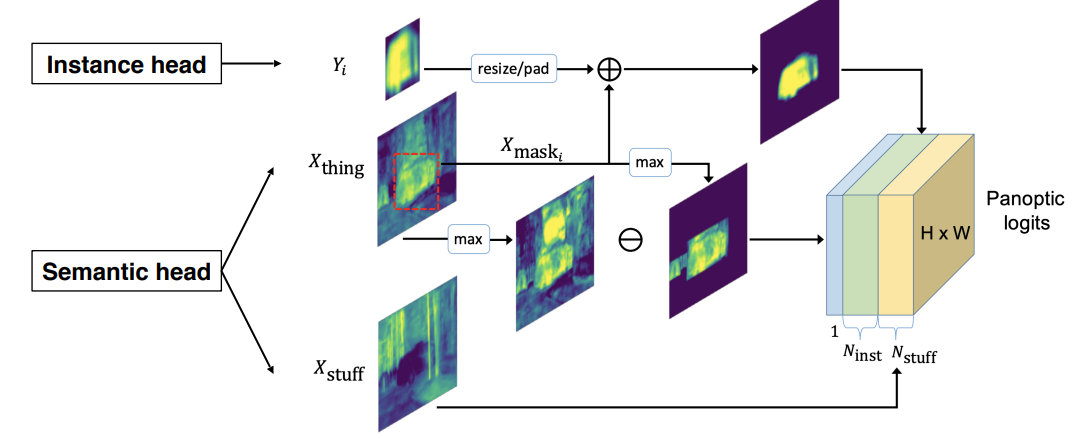
- Semantic head와 Instance head에서 Feature를 추출
- Instance head에서는 각 Object에 대해서 mask Feature를 얻음
- Semantic Head에서는 Instance의 클래스가 겹치는 $X_{thing}$ 과 배경 $X_{stuff}$ Feature를 받아옴
- Instance Feature를 적절히 Resize하여 가공하고 Semantic Head의 $X_{thing}$ 과의 합연산을 통하여 각 물체에 대한 Instace Mask를 얻는다
- Segmentation Feature에서 Max값만 추출한 Feature Map에서 Instance Feature와 합연산 처리가 된 부분을 제거한다
- 이는 Unknown Class에 해당하는 새로운 채널로 추가된다
- Semantic Feature와 Instance Feature간의 충돌을 해결해 주는 역할을 한다
- 2와 3에서 만들어진 Feature들과 배경을 나타내는 $X_{stuff}$를 Concat시켜서 최종적인 Panoptic Segmentation mask를 예측
VPSNet
- UPSNet을 Video에서도 동작하도록 디자인된 모델
- 기존 UPSNet과 동일한 구조를 가지고 추가적으로 Track Head가 추가되어 동일 객체에 대해서 Instance Segmentation이 잘 진행되도록 한다
Landmark Localization
얼굴이나 사람의 포즈를 추정하고 Tracking 하는데 사용되는 기술이다

Coordinate regression
- Landmark 별 Regression을 진행하는 방법
- 기존에 많이 사용하던 방식이지만 부정확 했다
Heatmap Classification
- Segmentation과 비슷하게 모든 픽셀에 대해서 Landmark 인지를 연산하는 방법
- Coordinate regression보다 좋은 성능을 보여주었지만, 모든 픽셀에 대하여 연산을 진행하다보니 더 많은 연산이 필요하다
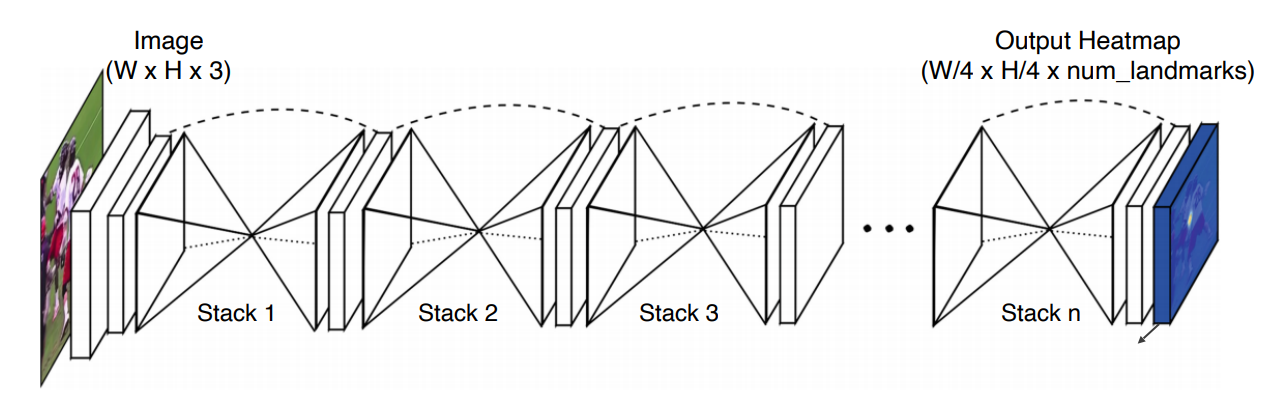
Hourglass Network
- Stacked hourglass modules
- Skip Connection
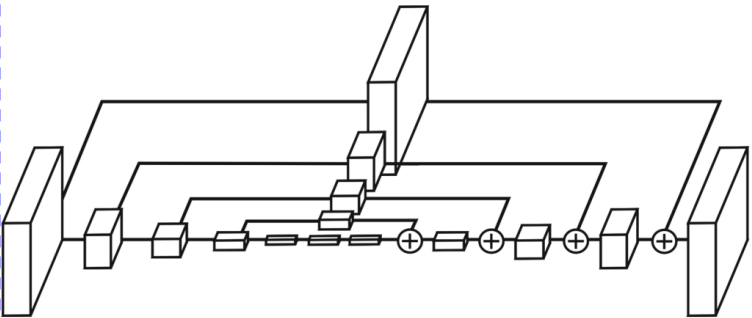
Hourglass Module
- Unet과 비슷한 구조
- Feature를 대칭되는 Layer로 넘겨줄 때 CNN을 통해서 걸러지고 + 연산이 이루어진다
DensePose
이미지를 3D Surface(UV map)로 표현해주는 모델
- Fast R-CNN + 3D surface regression branch
RetinaFace
- 얼굴에 대해서 여러가지 task를 동시에 처리하는 모델
- Gender Classification
- Face Detection
- 5 Landmark Regression
- 3D Mashup
- FPN + Multi-task branches
- Backbone + target Branch
Detecting objects as keypoints
CornerNet
Top-left, Bottom-right 2 point만 예측하면 BBox를 만들수 있다는 것에서 시작한 모델
CenterNet
CornerNet에서 Center까지 같이 예측하는 모델
추가적으로 Center를 예측하면서 성능의 상승이 이루어졌다
- CenterNet(1)
- Top-left, Bottom-right, Center
- CenterNet(2)
reference