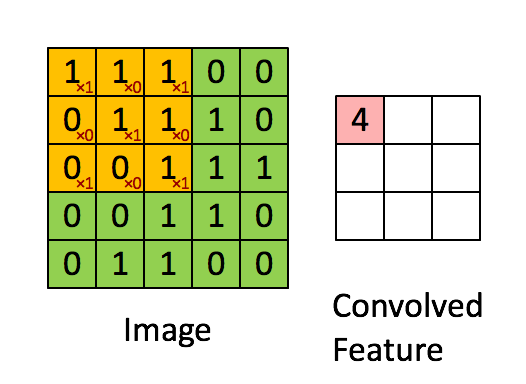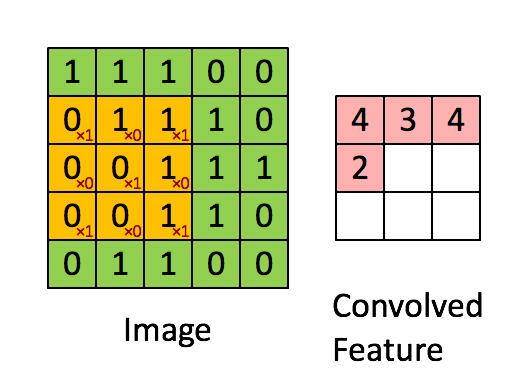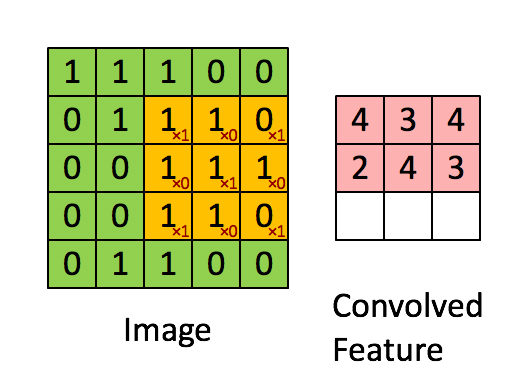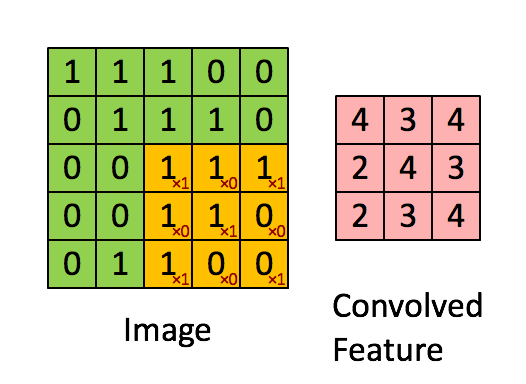
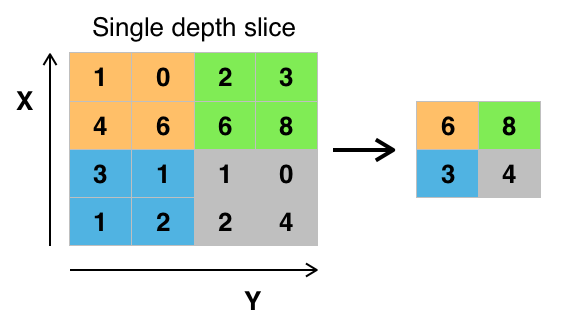
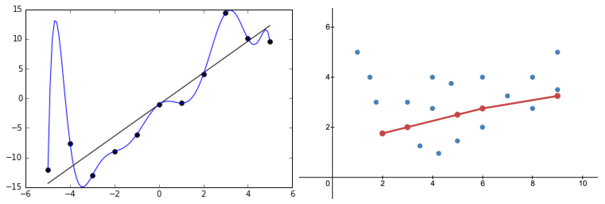
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
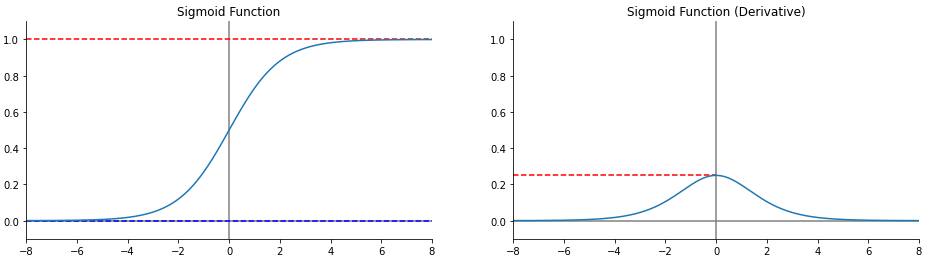
| def drow_graph(x, y, d, function_name, y_lim, x_lim, minmax):
fig, ax = plt.subplots(1, 2, figsize=(16, 4))
ax[0].plot(x, y)
ax[0].set_title(f"{function_name}")
ax[1].plot(x, d)
ax[1].set_title(f"{function_name} (Derivative)")
if minmax:
ax[0].axhline(max(y), color="red", linestyle="--", zorder=1)
ax[0].axhline(min(y), color="blue", linestyle="--", zorder=1)
ax[1].axhline(max(d), color="red", linestyle="--", zorder=1, xmax=0.5)
for i in range(2):
ax[i].axvline(0, color="gray", linestyle="-", zorder=0)
ax[i].axhline(0, color="gray", linestyle="-", zorder=0)
ax[i].set_xlim(x_lim)
ax[i].set_ylim(y_lim)
ax[i].spines['top'].set_visible(False)
ax[i].spines['right'].set_visible(False)
|