10/07일
오늘도 gitlab에서 CI/CD pipeline 구축 체험을 해보았다. (CI/CD에 대해 조금 알아보았는데 지금하는건 체험 수준)
오늘 작업을 하면서 알게된점에 대해서 적어보려한다.
gitlab에는 안전한 업데이트(?)를 위한 기능으로 protected branch, protected tags를 지원한다.
protected branch
마스터, 메인브랜치 같은 언제나 잘 작동하는 올바른 코드가 올라가 있어야 하는 브랜치를 특정 행동으로부터 보호하기 위한 조치이다.
protected branch로 설정하면 항상 올바른 커밋을 push나 merge 하기 위해 룰을 지정할 수 있다.
ex) Pull Request를 merge하기전에 항상 코드리뷰를 n명의 리뷰어에게 거쳐야 하거나, CI 테스트를 통과한 브랜치만이 merge가능하다.
protected branch와 비슷하게 잘못해서 코드를 업데이트 하거나 삭제하는것을 예방할수 있다.
gitlab 에서 Protected tags는 삭제하는것이 불가능하다.(강제로 할 수는 있는데 권장하지 않음)
보통 CI/CD를 통과하고 release할 branch에 release version으로 tag를 단다.
직접 protected tags로 지정하거나, wildcrads를 이용하여 특정 규칙을 만족하면 protected tags로 설정하는것이 가능하다.
CI(Continuous Delivery)
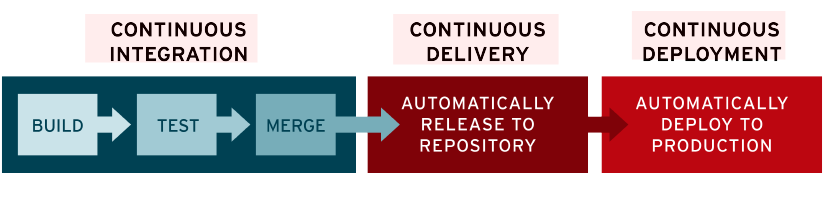
CI(지속적인 통합)이라고도 한다. CI를 통하여 개발자들은 협업을 하면서 코드의 변경 사항을 공유브랜치로 병합하는 작업을 더욱 수월하게 수행할 수 있다.
개발자가 push한 변경사항이 병합될때 이 변경사항이 기존의 애플리케이션을 손상시키지 않도록 pipeline을 통한 테스트를 한다.
CD(Continuous Delivery or Deployment)
CD(지속적인 제공)는 유효한 코드를 repository에 자동으로 릴리즈한다.
CD(지속적 배포)는 repository에 릴리즈된 유효한 코드를 자동으로 실행하는것을 말한다.
애플리케이션을 배포할때 애플리케이션 전체를 한번에 실행하는것이 아닌 작은조각(모듈)으로 나누어 실행하면 좀더 리스크 관리를 하기 쉬워진다.
출처
RedHat - what is ci/cd