An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
논문 링크 : https://arxiv.org/pdf/2010.11929.pdf
원래 이번 논문 리뷰는 Swin Transformer에 대해서 다루려고 했는데 ViT의 내용을 알지 못하면 풀어서 이야기 할수 없는 부분이 많아서 이번 논문은 CV분야를 CNN에서 transformer로 판도를 바꿔버린 ViT에 대해서 다룹니다
간단 요약
- Image Data + Multi head Self Attention
- Position embedding을 통해 token에 위치 정보를 추가
- Cls Token을 이용한 Classification
- 그 외의 부분은 NLP의 Transformer 구조를 그대로 가져옴
- 학습을 위해서는 매우 많은 사전 Data가 필요하다
- 데이터가 많을 수록 더 robust한 모델이 만들어진다
들어가기 앞서
Inductive bias (귀납 편향)
Inductive bias은 Model이 접해보지 못한 input 데이터에 좋은 성능을 내기 위해 사전에 설정된 가정을 이야기한다
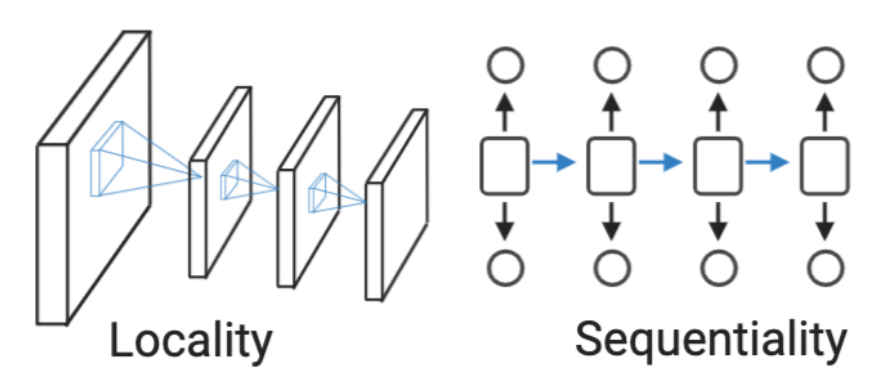
CNN 계열 : Locality
- 하나의 pixel에 대하여 주변 pixel또한 비슷한 데이터를 가지고 있을것이라고 가정
- 부분적인 데이터를 모아서 보기 때문에 Global한 영역에 대해서는 처리가 어렵다
- 이를 해결하기 위해 Receptive field를 넓히는 등 여러 연구가 이루어지고 있다
RNN 계열 : Sequentiality
- 특정 정보는 비슷한 시간대에 모여있을 것이라고 가정하고 설계 된 모델
- 순차적이지 않고 먼 뒤쪽에 연관된 데이터가 나오는경우 (ex. 대명사) 예측이 제대로 이루어 지지않음
이러한 Inductive bias가 강하게 설정 되어 있을 수록 특정 데이터에 대해서 적은 Data로도 좋은 performence를 보여줄 수 있다
- 그 데이터에 특화된 모델이기 때문이다
Transformer와 Inductive bias
- Vision Transformer는 추후에 설명할 Positional Embedding과 Self Attention을 활용하여 이미지의 모든 정보(Global)를 활용하여 연산을 한다
- 부분적으로 이미지를 취합하여 예측하는 CNN보다 약한 가정이 들어갔다 볼 수 있다
논문에서 제안한 Point
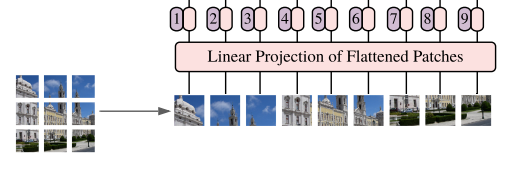
1. Patch 분할을 통한 image Token화
ViT에서는 이미지를 Transformer에 넣기위해 다음과 같은 과정으로 Token화 시켜준다
- 이미지를 Patch 사이즈로 분할한다 (2-d Matrix : $P \times P \times 3$)
- $P \times P \times 3$의 길이의 1-d vector로 Patch를 변환시켜준다
- Fully Connected Layer를 통하여 Linear Projection을 통해서 같은 차원을 가지는 Embedding Vector를 생성한다
2. Transformer for Classification
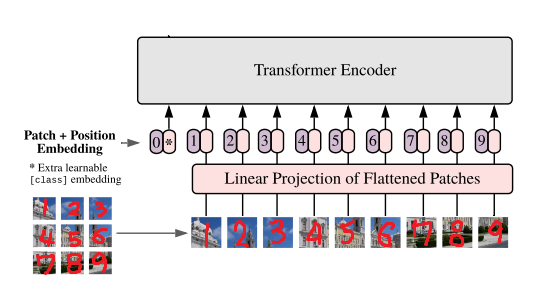
- ViT는 Input에 Image로 부터 생성된 Token을 입력한다는 점을 제외하면 Transformer의 구조를 그대로 사용하였기 때문에 기존 NLP의 BERT와 매우 흡사한 구조를 가지고 있다
- BERT의 Single text Classification과 같이 Transformer를 Classfication Model로 사용하기 위해 Classfication Token을 0번에 입력한다
- 학습 가능한 Parameter로 생성을 하여 학습을 통해서 추후에 결정된다
- 또한 Patch의 위치 정보를 가지고 있는 Position embedding을 각 token에 더해준다
- (Patch 개수 + 1) x (image token size) 의 크기를 가지는 Parameter
- 0번은 Classfication Token에 더해지고 나머지 번호는 각각의 순서대로 Patch에 더해지게 된다
- Classfication Token과 마찬가지로 학습 가능한 Parameter로 생성을 하여 학습을 통해서 추후에 결정된다
- 2차원 구조의 Position embedding을 사용했었지만, 1차원 구조보다 더 좋지않은 성능을 보여주었기 때문에 사용하지 않는다
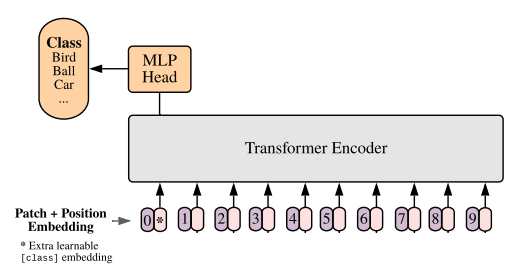
- 마지막으로 Classfication Token 위치의 출력층에 FC Layer를 두어서 분류의 대한 예측을 진행한다
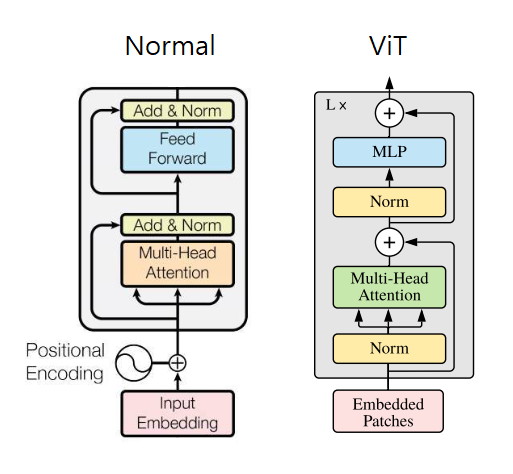
3. ViT Transformer Encoder
- Multi Head Attention 전에 Layer Normalization을 진행한다
- 자세한 이유는 아래의 논문을 참고
ViT의 한계
Inductive Bias가 작기 때문에 충분한 데이터를 확보하지 못한 경우에는 성능이 떨어지게 된다- Transformer의 고질적인 문제
- 이부분에 대해서 멘토링 시간에 새로운 논문을 소개해 주셔서 읽고 추후 리뷰를 통해 이야기 하겠습니다
- Image의 사이즈가 커질수록 만들어지는 Patch의 개수가 늘어나기 때문에 모델에 필요한 Parameter가 기하급수적으로 증가한다