오늘 한 일
- Efficient Det mmdetection에 넣어서 실행
- Bifpn 버그 수정
2. 피어세션에서 한 것
- Efficient Det TTA에 대해서 조원들과 이야기
- 사이즈가 고정된 모델이기 때문에 Multi scale이 불가능하다
3. 하루 느낀점
- 컨디션이 나가버려서 몸상태가 상당히 좋지 않은 하루였다
- 내일은 마저 p-stage에 대해서 정리를 해야겠다
논문 링크 : https://arxiv.org/pdf/2010.11929.pdf
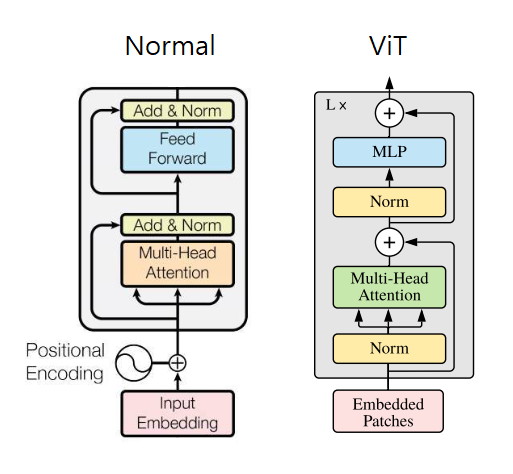
원래 이번 논문 리뷰는 Swin Transformer에 대해서 다루려고 했는데 ViT의 내용을 알지 못하면 풀어서 이야기 할수 없는 부분이 많아서 이번 논문은 CV분야를 CNN에서 transformer로 판도를 바꿔버린 ViT에 대해서 다룹니다
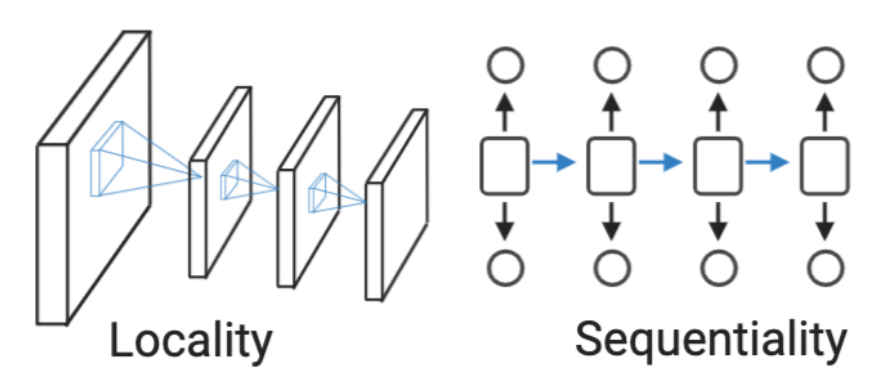
Inductive bias은 Model이 접해보지 못한 input 데이터에 좋은 성능을 내기 위해 사전에 설정된 가정을 이야기한다
CNN 계열 : Locality
RNN 계열 : Sequentiality
이러한 Inductive bias가 강하게 설정 되어 있을 수록 특정 데이터에 대해서 적은 Data로도 좋은 performence를 보여줄 수 있다
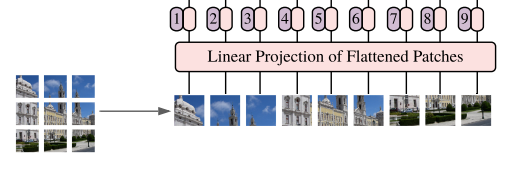
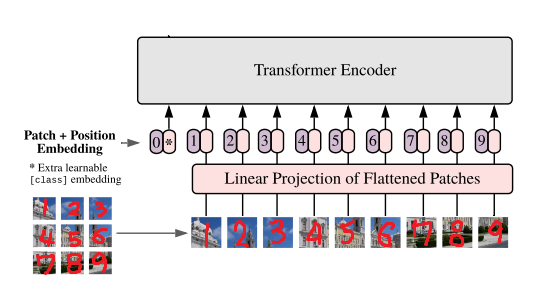
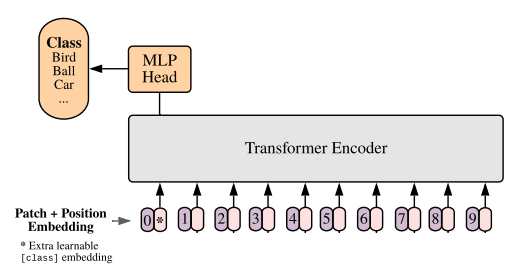
ViT에서는 이미지를 Transformer에 넣기위해 다음과 같은 과정으로 Token화 시켜준다