Global Interpritor Lock
GIL. Global Interpritor Lock.
Global Interpritor Lock(GIL)이란 Python에서 오직 하나의 Thread만 동작하도록 컨트롤하는 Lock(또는 Mutex)이다.
이 말은 타임라인상에 오직 하나의 Thread만 실행될 수 있다는 것을 말한다. Single Thread를 사용하는 코드에서는 그렇게 큰 영향을 주지 않지만, Multi-Thread를 사용하는 코드에서는 병목현상을 일으킬 수 있다.
GIL이 어떻게 동작하는지 한번 살펴보자
위에서 이야기 한 것처럼, GIL에서는 오직 하나의 Thread만 활성화되어서 코드를 실행하는데 이는 아래의 그림처럼 그려낼 수 있다.
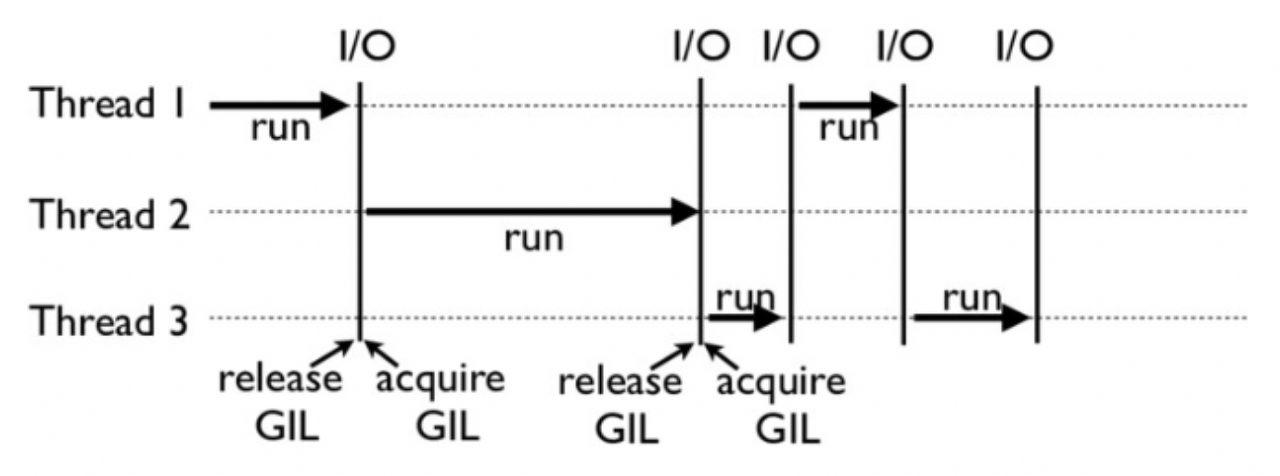
Thread가 전환 될 경우에는 기존의 Thread의 작동이 멈추고 동작을 시작하게 된다.
기존의 하던 작업들을 멈추고 다른 Thread로 넘겨야 하기 때문에 context switch가 일어나게 된다.
그러면 왜 GIL을 사용할까?
먼저 왜 GIL을 사용하는지 알기 위해서는 Python의 Garbege Collector(GC)에 대해 알고 있어야 한다. (GC에 대한 자세한 내용은 추후에 다룰 예정이다) 고급언어인 python에서는 C언어와 다르게 자동으로 메모리 관리를 해주는 GC라는 것을 사용한다.
이 GC는 오브젝트가 얼마나 많이 참조(실행)가 되었는지를 카운팅하는 reference count 라는 것으로 메모리에서 삭제할지 유지할지를 결정한다. 하지만 동시에 여러군데에서 참조가 이루어 질 경우 Race Condition 등의 문제들이 발생 할 수 있기 때문에 이를 방지하기위해 Mutex나 Semaphore등의 Lock이 필요했는데 이것을 Python에 존재하는 수많은 Object에 전부 적용하는것은 성능상으로도 좋지 않을 뿐만 아니라, Deadlock 같은 매우 치명적인 위험상황이 발생 할 수 있었다
그래서 선택한것이 따로 Object에 Lock을 두지 않고, 타임라인에서 실행되는 Thread를 딱 하나만 두도록 Interpritor를 Mutex로 잠궈버렸다. 이렇게 되면 여러곳에서 동시 참조가 되지않으니 성능의 하락 없이 위의 동시참조의 문제를 해결하게 된것이다
그러면 python에서는 병렬화된 코드는 어떻게 써야하나
- Multi Process를 사용한다
Thread를 막아버린것 이기 때문에 Multi Processing을 사용하면 잘 돌아간다. 물론 Process간에 공유자원을 가지기 위해서는 많은 작업들이 필요로 하기 때문에 context switching이 발생하여 Thread에 비해 속도가 늦을 것이다. 하지만 Windows는 OS 보안상 이유로 이걸 막아버렸다. - Multi Threading을 사용한다
아까 Multi Threading을 막아놨다고 했는데 뭔 소리냐 할 수 있지만, CPU에서 대부분의 연산이 돌아가는 코드를 제외한 I/O Bound 계열의 문제들은 file system과 Network의 하위 컴포넌트에서 돌아가기 때문에 Single보다 더 빠르게 진행 할 수 있다. - 굳이 사용하고 싶다면 PyPi나 Jython 같은 다른 Python implementation으로 사용하는 방법도 존재하지만, 그 코드가 python에서와 똑같이 동작할 보장은 없다
- 그리고 numpy나 Scipy등의 ML에서 많이 사용하는 Module들은 C기반으로 만들어져서 GIL의 굴레에서 자유롭게 연산이 된다고 한다.