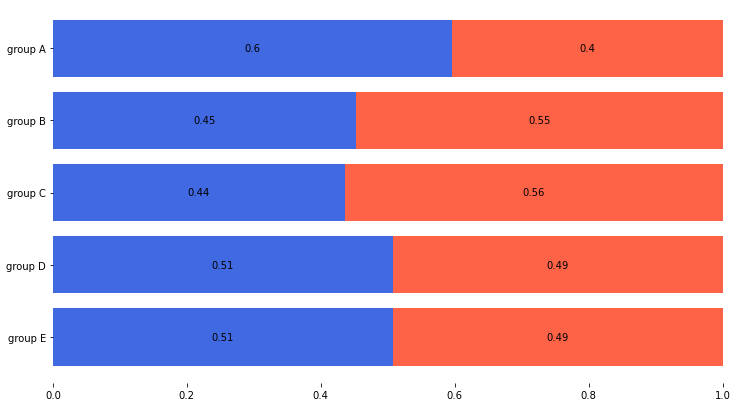
for ix inrange(5): ax[ix].set_title('ax[{}]'.format(ix)) # make ax title for distinguish:) ax[ix].set_xticks([]) # to remove x ticks ax[ix].set_yticks([]) # to remove y ticks fig.tight_layout() plt.show()
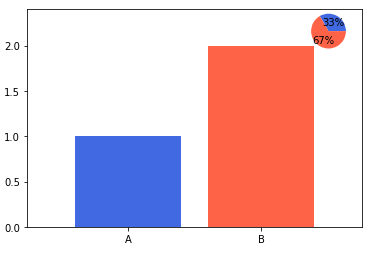
group = group.sort_index(ascending=False) # 역순 정렬 total=group['male']+group['female'] # 각 그룹별 합
for name, color inzip(['male', 'female'], ['royalblue', 'tomato']): rects = ax.barh(group[name].index, group[name]/total, left=group['male']/total if name == 'female'else0, color=color) ax.bar_label(rects, fmt='%.2g', label_type='center')
ax.set_xlim(0, 1) for s in ['top', 'bottom', 'left', 'right']: ax.spines[s].set_visible(False)
plt.show()
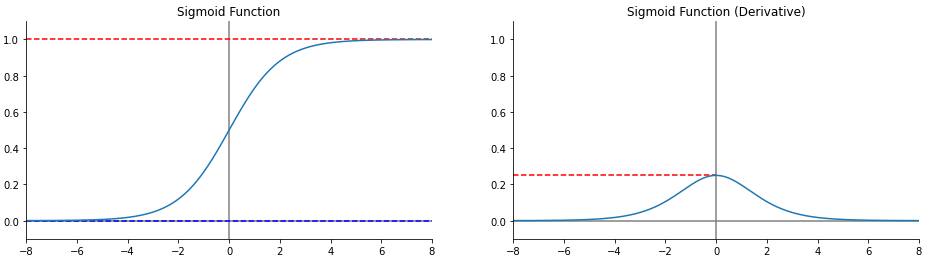
Overlap
2개의 그룹만 비교할때 사용하기 좋은 방식
3개 이상은 파악이 어렵다
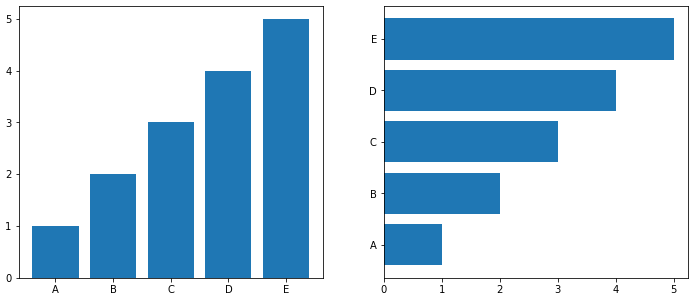
같은 축을 사용하기 때문에 비교하기 쉽다
Bar보다는 Area에서 더 효과적이다
1 2 3 4 5 6 7 8 9 10 11
group = group.sort_index() fig, axes = plt.subplots(1, 1, figsize=(8, 6))
Garbage Collector(이하 GC)는 메모리 관리 기법중 하나로 동적으로 할당했던 메모리 영역 중에 필요없게 된 부분을 해제하는 기능이다. C, C++등의 언어들은 수동메모리 관리를 전재로 설계되어 malloc, free등의 함수로 직접 메모리를 관리 해주어야 하지만, Python, Java, C# 같은 고급 언어들은 GC가 내장되어 있어 자동으로 메모리 관리를 해준다.
Python GC의 작동방식
Python의 GC는 reference count + Generational GC 방식으로 메모리를 관리한다.
python의 객체들은 모두 reference count를 가지고 있으며 이것을 통해서 GC가 언제 메모리에서 제거할지를 판단한다. 참조가 이루어지면 reference count가 1증가하고, 참조가 끝나면 1감소한다. 최종적으로 0이 되면 GC에서 더이상 필요없는 오브젝트로 판단하고 메모리에서 삭제한다.
이러한 방식은 프로그래머가 어느정도 오브젝트의 메모리 할당 해제 시점을 유추 할 수 있고, 대부분 사용된 직후 해제되기 때문에 캐시에 저장되어 있을 확률이 높아 빠르게 할당 해제가 이루어지는 장점이 존재한다.
하지만 아래와 같은 단점 또한 존재한다. 두개 이상의 객체가 서로 가리키고 있을 경우(순환 참조) reference count가 0까지 내려가지 않는 상황이 발생 할 수 있다. 또한 Multi Thread 환경에서는 공유자원에 대한 참조가 되기 때문에 추가적인 Lock 등이 필요하거나, 지속해서 GC에서 판단하는 프로세스를 거쳐야 하기 때문에 수행 성능의 저하 등의 문제가 발생 할 수 있다.
이러한 단점들을 해결하기 위해 Python에서는 순환 참조를 탐지하는 알고리즘과, 보조적인 Generational GC를 두었고, GIL로 Multi Threading에 제한을 걸어 버렸다.
Generational GC
새롭게 할당된 오브젝트일수록 금방 메모리에서 해제될 확률이 높다는 통계에서 기반한 메모리 관리방법이다. 각각의 오브젝트가 GC가 실행하고나서 메모리에서 해제되지 않으면 다음 세대로 넘어가게 되는 방식인데 더 젊은 세대(금방 생성)일수록 자주 GC의 프로세스에서 할당 해제할 오브젝트인지 판단이 내려지게 된다.
이 과정을 보조적으로 추가하면서 python에서는 조금더 효율적으로 메모리를 관리 하고 있다.