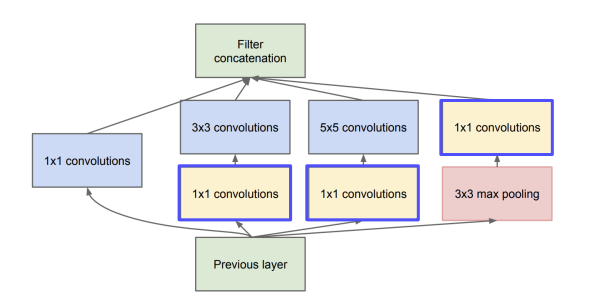
Convolution Neural Network (CNN)
- 시각적 데이터르 분석하는데 사용되는 인공신경망
- CNN은 크게 Convolution Layer, Pooling Layer, (Fully Cunnect Layer)로 구성된다

Convolution layer
- 합성곱 연산이 진행되는 레이어
- parameter의 수는 $kernel_size \times Channel_in \times Channel_out$으로 계산된다
- 이미지 처리를 할 시에 Fully Connected Layer보다 parameter 수가 월등하게 적다
- 실제 연산 이미지
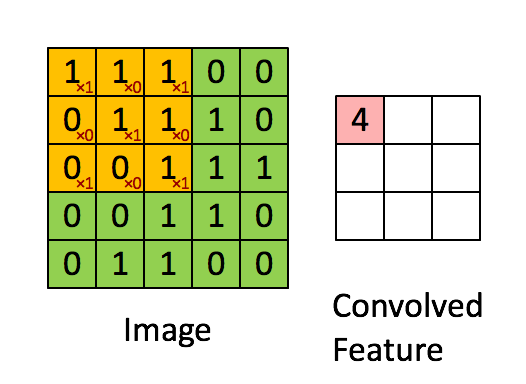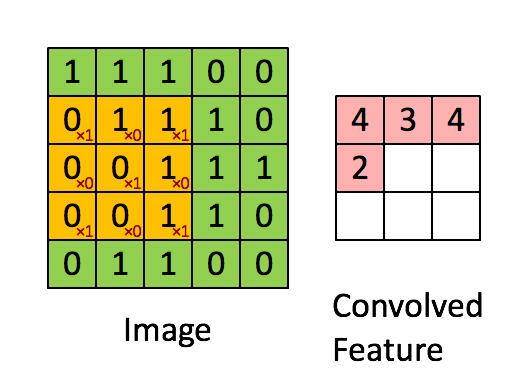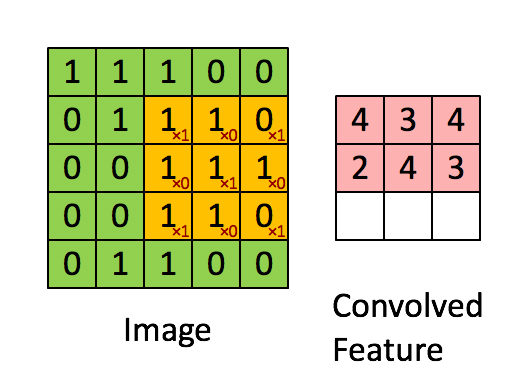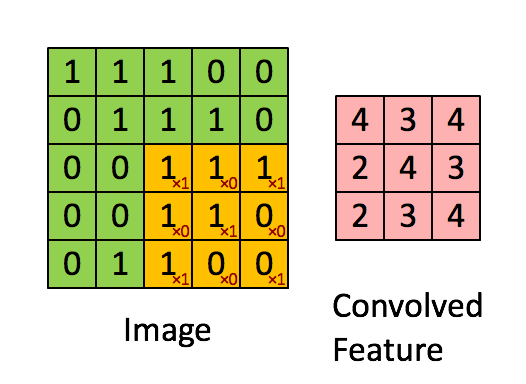
- input과 output의 크기는 아래와 같이 계산된다
- input : $(N, C_{in}, H_{in}, W_{in})$
- output : $(N, C_{out}, H_{out}, W_{out})$
- stride : 연산이 이루어지는 간격
- padding : 차원을 확장시켜 convolution 연산후에도 크기가 일정하게 유지되도록 한다
- kernel : convolution 연산을 하는 주체, filter이기도 하다
- N : batch size
- C : Channel 수
- W : 연산될 Matrix의 가로 길이
- H : 연산될 Matrix의 세로 길이
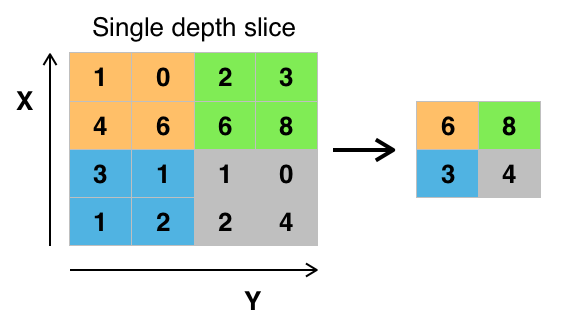
Pooling Layer
- 일정 범위안의 값들을 대표하는 하나의 값으로 압축하는 down sampling 기법
- W와 H을 줄여서 차원을 축소하고, 연산에 필요한 parameter 수를 줄인다.
1x1 Convolution
- kernel size가 1,1인 convolution 연산을 하는것
- input, output의 W, H는 일정하지만 channel수가 감소한다.
- WHY?
- channel 수를 줄여서 차원축소를 시키고, 추후에 연산에 필요한 parameter 수를 줄인다
$$
H_{out} = \left[ \frac{H_{in} + 2 \times \operatorname{padding[0]} - \operatorname{kernel_size[0]}}{\operatorname{stride}[0]} +1 \right]
$$
$$
W_{out} = \left[ \frac{W_{in} + 2 \times \operatorname{padding[1]} - \operatorname{kernel_size[1]}}{\operatorname{stride}[1]} +1 \right]
$$
reference