Object Detection
- 특정 오브젝트가 어디에 위치해있고, 그 오브젝트가 무엇인지를 탐지하는 Task를 말한다
- Classification과 Box Localization을 같이 하는 Task
- 자율주행이나 OCR등에서 사용된다
- Classification과 Box Localization을 따로 연산하는 Two Stage 방식과 동시에 연산하는 One Stage 방식이 존재한다
Two Stage Object Detection
- 이미지의 BBox를 추출하고 이 BBox로 Classification을 진행하는 모델을 말한다
- R-CNN 계열의 모델이 여기에 속한다
- 2단계로 연산을 하기 때문에 연산속도는 느린편에 속하지만 정확도가 높다
Selective Search
- 이미지로부터 BBox를 만들어 내는 알고리즘
- 이미지의 색상단위로 Over Segmentation을 진행하고 규칙에 따라 점점 합쳐나가는 알고리즘
- Color Similarity
- Texture Similarity
- Size Similarity
- Shape Similarity
- A final meta-similarity measure

R-CNN
Classification이 바로 Object Detection에 응용된 모델이다.
모델은 아래와 같이 간단한 단계로 BBox를 구하고, Classification을 진행한다
- Selective Search를 사용하여 물체가 있을 법한 후보를 선택한다(~2k)
- 선택된 후보군 전체에 대해서 이미지의 크기를 재가공하여 Classification 모델에 집어넣는다 (2000개의 후보들에 대해서 모두 CNN, SVM 연산)
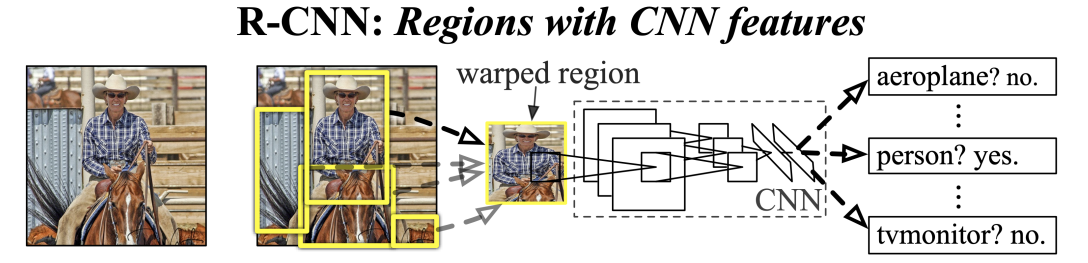
- RCNN은 초기 모델인 만큼 다양한 문제점 또한 존재한다
- BBox를 뽑아내는 알고리즘은 Seletive Search 같은 Huristic 알고리즘이기 때문에 학습이 불가능해서 성능향상이 크지 않다
- Selective Search는 Cpu에서 연산이 이루어지기 때문에 시간도 많이 소요된다
- 후보 전체에 대하여 Classfication을 한번씩 진행하다보니 연산량이 많아져서 시간소모가 크다
Fast R-CNN
기존의 R-CNN의 연산이 매우 오래걸린것을 해결한 모델이다.
Roi Pooling을 이용하여 모든 후보에 대해서 Convolution Network 에 입력하던것을 단 1번으로 줄였다.
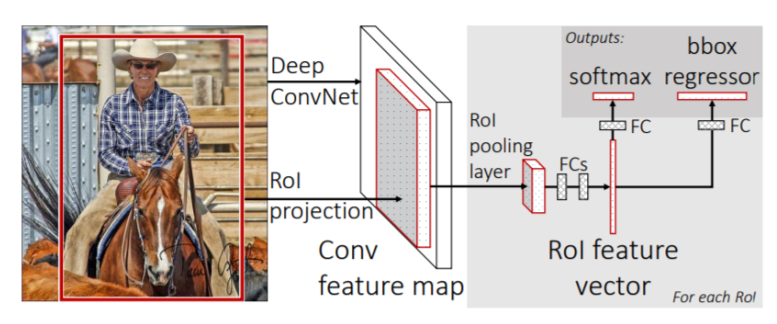
RoI Pooling을 이용한 Fast R-CNN
- 전체 이미지를 CNN에 통과시켜서 Feature Map을 추출한다
- Seletive Search등의 Region Proposal Method를 이용하여 RoI를 찾는다
- 찾은 RoI를 미리 뽑아둔 Feature Map에 투영하여 RoI에 해당하는 부분에 대해서 Pooling을 진행해서(SPPNet 이용) Classification을 위한 FC Layer의 input Size에 맞춘다
- softmax연산을 통하여 Classification을 진행한다
- Bounding Box Regression을 통하여 BBox의 위치를 재조정한다
R-CNN에서 RoI Pooling을 도입하여 연산속도면에서 획기적인 발전을 이룩한 모델이지만 여러 한계점이 존재했다
- 아직도 Seletive Search를 사용하기 때문에 BBox 검출에 대해서 큰 학습이 이루어지지 않았기 때문에 성능면에서는 큰 차이가 없다
- 모델 뒷부분의 성능은 개선되었지만 BBox 검출 속도는 그대로기 때문에 Bottleneck 현상이 발생한다
Faster R-CNN
Fast R-CNN의 단점이었던 Seletive Search를 Nueral Network(RPN)로 대체함으로써 End to End로 학습이 가능해진 모델이다
- Keyword
- RPN
- NMS
- IoU (Intersection over Union)
- 두 BBox가 얼마나 잘 겹쳐있는지를 판단하는 Metric
RPN
R-CNN 계열에서 RoI를 생성하던 Region Proposal Method를 대체하는 Network이다.
RPN에서는 다양한 모양의 BBox를 출력 해 내기 위해서 미리 특정 크기의 Anchor Box들을 구현해 놓고 이 Anchor Box들과 대조하여 IoU를 계산한다.
- Faster RCNN 에서는 3개의 Scale과 3개의 비율을 조합하여 9개의 Anchor Box를 미리 정해 두었다.
RPN에서는 Slide Window 방식으로 Anchor Box를 이용하여 물체가 존재하는지에 대한 유무와 BBox의 delta 값을 Feature Map으로 부터 추출한다
- Delta : 고정된 크기의 Anchor Box를 실제 BBox에 일치시키는 이동 정보를 담고있는 벡터를 말한다
결론적으로 RPN을 학습시키면 물체가 존재할 가능성이 높은 BBox를 도출하는 쪽으로 학습이 진행된다
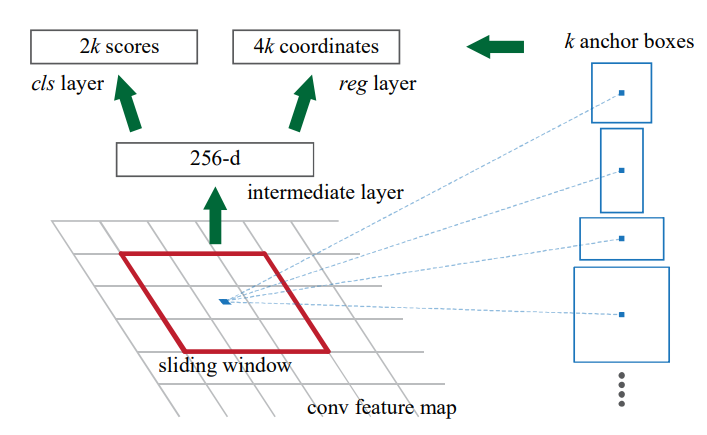
RPN으로 부터 추출된 BBox 좌표를 기준으로 기존에 뽑아두었던 Feature Map에 RoI Pooling을 적용하고 Classification과 Box Regression을 진행한다
Non Maximum Suppression
- RPN으로 생성된 수많은 BBox중 중복되는 Box들을 지우는 알고리즘
- 동일한 클래스에 대해서 Sorting을 통해 Comfidence 순서로 정렬 시킨다
- 가장 Confidence가 높은 BBox와 IoU가 일정 이상인 BBox는 중복되었다고 판단하고 삭제한다
추가적인 사항
- 실제로 Faster RCNN을 학습시킬때는 RPN과 RCNN 모델을 따로 각각 학습을 시킨뒤에 붙였다고 한다
One Stage Object Detection
- 이미지의 BBox를 추출하면서 Classification까지 동시에 진행하는 모델을 말한다
- 1단계로 연산을 하기 때문에 실시간 처리속도가 높지만 정확도가 2 Stage Detector 보다 조금 떨어진다
YOLO
- One Stage Object Detection Model의 대표적인 모델
- Faster RCNN과 유사하게 Anchor Box와 Box Regression을 통해서 BBox를 예측한다
- Anchor Box의 위치를 찾는것과 동시에 Class Probability map을 생성한다
- Class Probability map과 BBox를 합쳐서 detection을 마친다
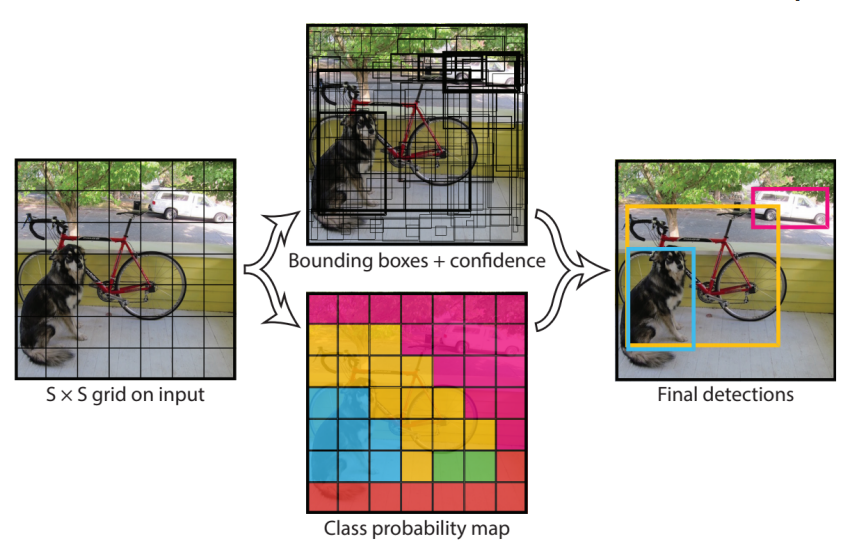
- 초당 처리 프레임 수는 Faster RCNN을 앞섰지만, 성능면에서는 조금 떨어지는 경향을 보였다
Single Shot MultiBox Detector(SSD)
- YOLO의 정확도 문제가 개선된 One Stage 모델이다
- 아래의 그림과 같이 여러개의 Feature Map에서 Anchor를 이용하여 Feature를 추출한다
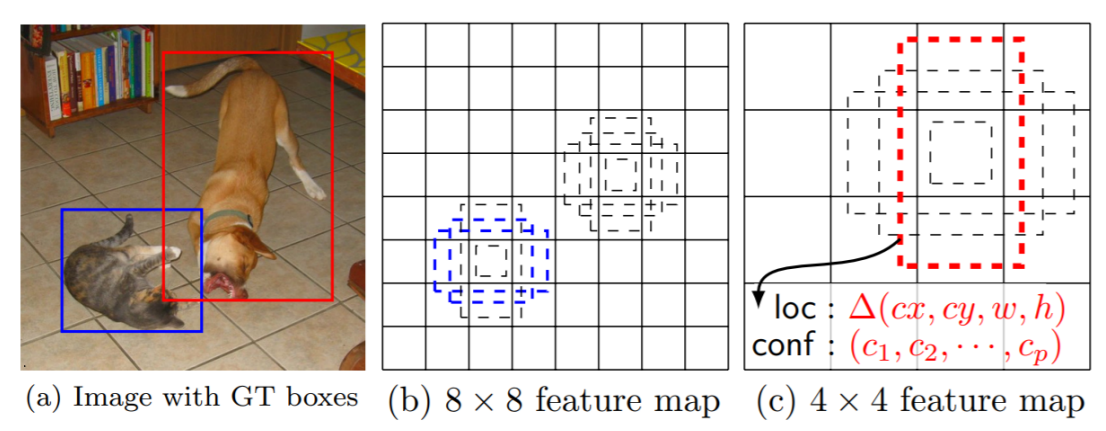
- 각 레이어마다 Anchor Box에 대한 정보들을 종합하여 최종적으로 NMS를 통해 겹치는 BBox를 제거하여 결과를 낸다
- 이를 통하여 Yolo와 비슷한 수준의 처리속도와 Faster RCNN을 넘는 성능을 보여주었다

RetinaNet
- Focal Loss와 FPN구조를 도입함으로써 One Stage Detector의 성능을 더욱 끌어올린 모델 구조
- Keyword
- Focal Loss
- Feature Pyramid Network(FPN)
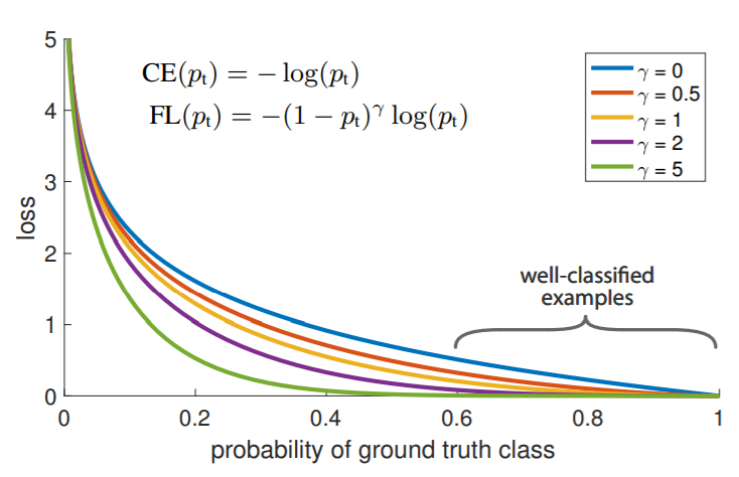
Focal Loss
- One Stage Detector의 고질적인 문제인 적은 Positive Sample 문제를 해결하기 위해 고안된 Loss 함수이다
- Positive Sample은 단 하나지만 Negative Sample은 엄청나게 많이 발생하기 때문에 Class imbalance 문제가 발생한다
- Cross Entropy loss로 부터 고안된 Loss 함수
- 맞추기 쉬운 Sample에 대해서 발생하는 weight를 낮추고 맞추기 힘든 Sample에 대해서는 높은 weight를 주게 된다
- loss값은 Focal loss가 작지만 같은 지점의 Gradient를 보면 Focal Loss가 훨씬 크다
Feature Pyramid Networks
- 서로다른 해상도의 Feature Map을 쌓아올린 형태를 가지는 CNN 모델이다
- 입력층에 가까울수록 Low Level의 Feature를 가지고, 출력층에 가까울수록 High Level(Global Level)의 Feature를 보유하는 CNN의 특성을 이용하였다
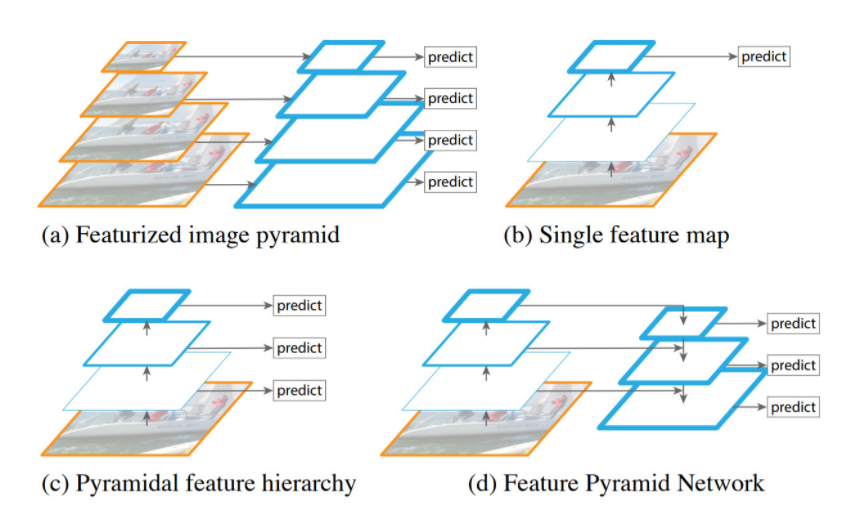
- (a)는 다양한 Scale의 Feature 맵을 사용해서 다양한 크기의 Object를 탐색하는 것이 가능하고 성능도 좋다. 하지만 여러장의 이미지에서 모두 Feature Map을 추출해야하기 때문에 느린 처리속도를 가진다
- 기존의 Yolo는 단일 Scale의 Feature 맵을 사용하는 (b) 방식을 사용했다. 모델구조가 단순하여 빠른 처리가 가능하지만, 성능이 떨어지는 단점이 존재한다
- SSD에서 사용한 방식인 (c)는 다양항 크기의 Feature Map을 사용하여 좋은 성능과 빠른 처리속도를 보여주었지만, Backbone을 지나서 충분하게 High Level 수준의 Feature들을 합쳐서 결과를 내기 때문에, 더 높은 해상도의 Low Level Feature Map(High Resolution map)을 사용 하지 않아 Small Object 검출에 한계가 있다고 논문에서 서술했다
- FPN에서는 (d)의 구조를 통하여 Low Level 부터 High Level 까지의 Feature Map을 전부 사용하여 검출이 힘든 작은 물체 까지 잘 검출하는 모습을 보여주었다
reference